Threat Modeling Your Dependencies - Part 2

Mitigating Third-Party Component Risk: Swapping the Cancer for Something Healthier
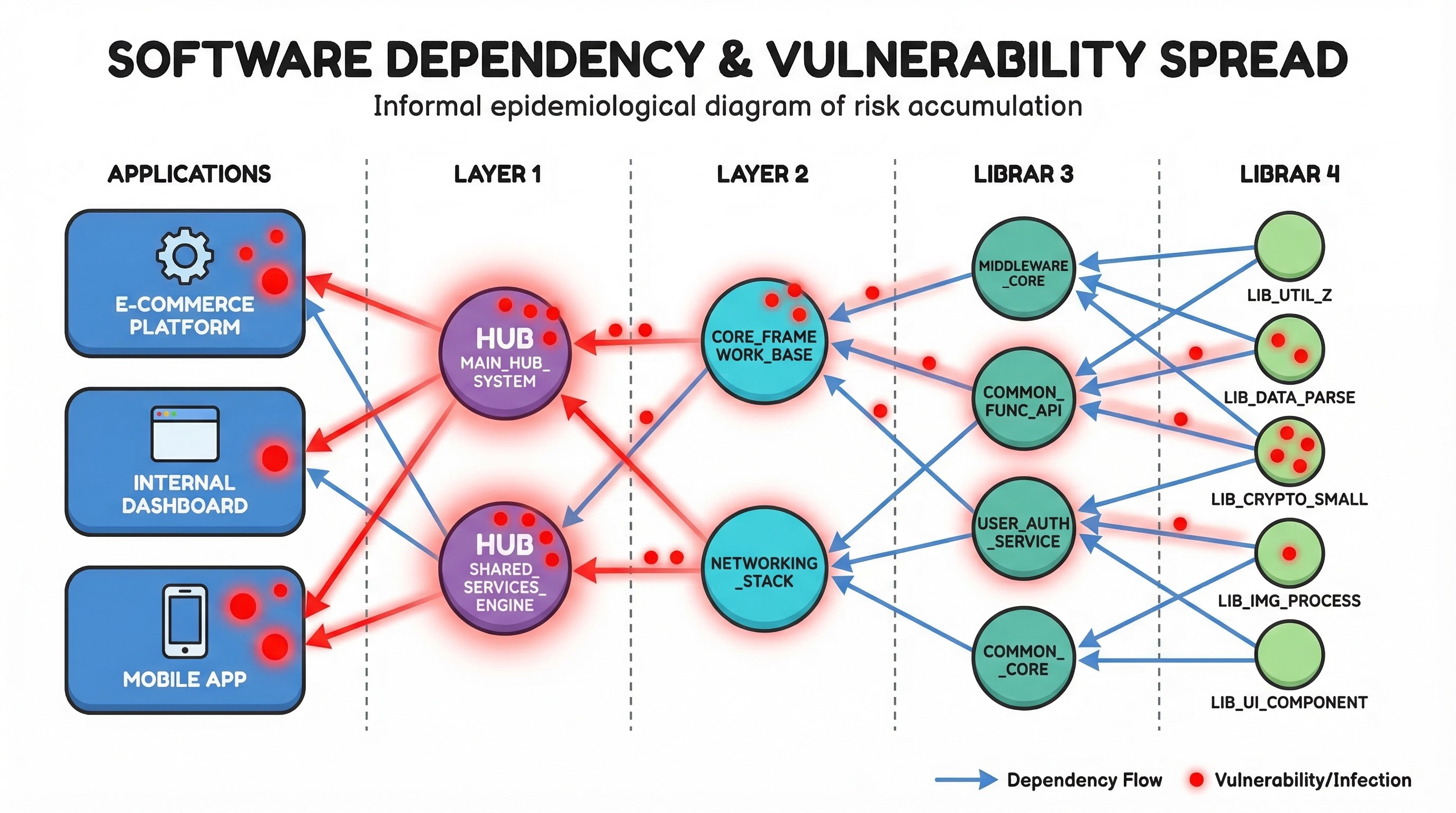
In my previous post, Threat Modeling Your Dependencies, I laid out how a single vulnerable third-party library can cascade through your ecosystem and poison hundreds of applications. We established the Supply-Chain Trust Score, a way to quantify and track that risk across your entire dependency graph.
But identifying the problem is only half the story. The question from the Threat Modeling Manifesto that should be ringing in your ears right now is: what can we do better?
The answer, when you think about it, is surprisingly straightforward. We know which components are dragging our effective trust scores down. We know what those components do. And we know how we’re using them. So what if we swap them for alternatives that offer similar functionality but are significantly more trustworthy?
The Case for Proactive Dependency Swapping
Let me paint the picture. You’ve run the trust scoring model from the previous article and you’ve identified that dodgy-json-parser has a direct trust score of 2.1. It ships CVEs monthly, the MTTR is 47 days, and its security practices don’t follow best practices. It sits at depth 2 in your dependency graph and has 85 transitive dependants across your ecosystem.
Right now, what most organisations do is react. A CVE drops, the team scrambles to patch or mitigate, a waiver gets raised, compensating controls get bolted on, and everyone moves on until the next CVE drops, which, if we’re being honest, is probably next month.
But here’s the thing: you could eliminate that entire class of reactive work by replacing the component with a more trustworthy alternative. Not when the next CVE hits, now, proactively, before the next fire starts.
This isn’t a new idea in principle. Most engineers have swapped out a library at some point because it was buggy, slow, or abandoned. What’s new is the ability to make that decision systematically, driven by trust score data, and to prioritise those swaps based on the business risk they reduce.
Finding Alternatives: The Data Sources
So where do we actually find these alternatives? There are several data sources that associate or list libraries with similar functionality, and when we combine them with our trust scoring model, we can make genuinely informed decisions.
LibHunt
LibHunt tracks mentions of open-source projects across Reddit, Hacker News, and dev.to, and uses that social signal data to build lists of alternatives and similar projects for any given library. If you know the GitHub URL of a library, you can simply swap github.com for libhunt.com in the URL to see its alternatives, a genuinely clever piece of UX.
The strength of LibHunt is its breadth. It covers projects across multiple ecosystems and languages, and the alternative mappings are community-curated, which means they tend to reflect what developers actually use as drop-in replacements rather than what’s theoretically equivalent. The limitation is that it’s driven by social signals, so niche or enterprise-internal libraries won’t have coverage.
libraries.io
Libraries.io is a cross-platform search engine that indexes metadata from over 30 package managers. It provides dependency data, version history, contributor activity, and crucially, a SourceRank metric that gives a quick signal of project health.
Where libraries.io really shines for our purposes is its API and its underlying dataset. You can query dependents and dependencies programmatically, which means you can build automated workflows that identify a component, find packages in the same category, and pull their metadata for comparison. The data is also available as a BigQuery dataset for large-scale analysis. The free tier has API rate limits (60 requests/minute), but for most use cases that’s sufficient. For enterprise-scale analysis, Tidelift offers a curated and validated version of the same underlying data.
Snyk Advisor
Snyk’s open-source Advisor tool provides health assessments for packages across npm, PyPI, and other ecosystems. It evaluates maintenance activity, security posture, community engagement, and popularity. While it doesn’t explicitly map “alternative” libraries the way LibHunt does, it’s invaluable for evaluating candidates once you’ve identified them. You can compare the health profiles of your current dependency and its potential replacement side by side.
deps.dev (Google Open Source Insights)
We’re already using deps.dev as one of the four data sources for the trust score itself, but it has an additional trick up its sleeve. The API includes a GetSimilarlyNamedPackages endpoint, originally designed for typosquatting detection, that can also surface packages with related names and purposes. More usefully, its BigQuery dataset lets you run queries to find packages that share similar dependency profiles or are used by similar sets of projects, which is a strong signal of functional equivalence.
Package Manager Native Tooling
Don’t overlook the package managers themselves. npm has keyword-based search and category browsing. PyPI has classifiers that group packages by functionality (e.g., Topic :: Internet :: WWW/HTTP :: Session). Maven Central has group-based discovery. Cargo has categories. These aren’t designed for “find me an alternative to X” specifically, but combined with trust score data, they can surface candidates you’d otherwise miss.
GitHub Topics and Ecosystem Tags
GitHub’s topic system provides another signal. Libraries solving similar problems tend to share topics like json-parser, http-client, or orm. Querying GitHub’s API for projects with matching topics, filtered by activity and star count, gives you a rough but useful starting list of candidates.
The Gap: Category-Level Discovery vs. Feature-Level Precision
The data sources above are genuinely useful, they’ll get you a list of candidates, and that’s a necessary starting point. But here’s where my concern arises: they all operate at the category level, not the feature level.
LibHunt tells you “these libraries are in the same space as your JSON parser.” Libraries.io tells you “these packages share similar dependency profiles and are used by similar projects.” GitHub Topics tells you “these projects are all tagged json-parser.” Even Snyk Advisor and deps.dev, while excellent for evaluating a candidate once you’ve found one, don’t help you answer the more specific question: does this alternative actually cover the specific features and APIs that my code depends on?
Think about it concretely. Your application uses dodgy-json-parser for three things: streaming deserialization of large payloads, custom date format handling, and a specific error recovery mode that silently skips malformed records. A category-level search will surface every JSON parser in the ecosystem and most of them won’t support all three of those features. You’ll spend engineering time evaluating candidates that look promising on trust scores but turn out to be non-starters because they can’t handle your streaming use case, or they throw on malformed input where your current library skips.
This is the fundamental limitation of the current approach. The alternative discovery sources are too broad, and the filtering happens too late, typically when an engineer sits down to start the migration and discovers that the “drop-in replacement” isn’t actually a drop-in at all.
What we actually need is feature-level alternative discovery: a system that understands which specific APIs and capabilities you’re consuming from a library, and then evaluates candidates against that specific usage profile rather than against the library’s full feature set.

The Building Blocks Exist — They Just Haven’t Been Connected
The good news is that the individual components needed to solve this problem already exist in various forms. They just haven’t been assembled into a single pipeline.
Reachability analysis gives us the input side. Modern SCA tools, Endor Labs, Semgrep, Aikido, and others, now perform function-level reachability analysis. They can tell you exactly which functions and code paths of a dependency your application actually invokes. Endor Labs, for example, uses source code as the ground truth and applies program analysis techniques to pinpoint every dependency in use, down to the functions being called. Semgrep’s researchers manually review security advisories and reverse-engineer patches to identify vulnerable components, then create rules to identify their usage. This is precisely the “what features are you actually using” data that alternative discovery needs, but today, these tools use that analysis exclusively for vulnerability prioritisation, not for surfacing replacements.
AI-assisted OSS selection is getting closer. Endor Labs’ DroidGPT feature combines ChatGPT with their proprietary risk data, allowing developers to ask conversational questions like “what packages in Go have a similar function as log4j?” and receive answers overlaid with risk scores. This is a step in the right direction, it moves beyond static category matching into something more nuanced. But it’s still operating at the library level, not the “which specific methods am I calling” level. It doesn’t analyse your call sites to determine which capabilities you need from a replacement.
Academic research has demonstrated method-level migration mapping. Researchers have formulated API migration as a combinatorial optimisation problem, using genetic algorithms to recommend suitable target APIs based on method signature similarity, documentation similarity, and co-occurrence patterns across real-world migrations. The results are genuinely promising, up to 100% precision for certain library migrations, but this is academic research, not a tool you can plug into a CI pipeline.
LLM-powered migration recommendation is emerging. LibRec, published in August 2025, is a framework that uses LLMs with retrieval-augmented generation (RAG) to automate alternative library recommendations. It learns from how real developers have actually migrated between libraries by extracting migration intents from commit messages. It’s built a benchmark of 2,888 migration records from Python repositories. This captures why people migrate (security, performance, maintenance, compatibility), which is closer to intent-aware recommendation. But it still operates at the library level rather than matching feature-by-feature against your actual usage.
Dependency knowledge graphs provide the reasoning infrastructure. DepsRAG is a multi-agent framework that constructs comprehensive knowledge graphs of dependencies, both direct and transitive, and lets you query them using natural language. The architecture is interesting because it could theoretically be extended to reason about “given the functions I’m calling in library X, which library Y covers the same ground?” The knowledge graph structure is well-suited to this kind of relational reasoning.
What a Feature-Level Alternative Discovery Pipeline Would Look Like
So what would the complete solution actually require? Let me sketch out the pipeline:

Step 1: Extract the usage profile. Use reachability analysis (static, dynamic, or both) to build a precise map of which APIs, functions, and capabilities your codebase actually consumes from the target library. This isn’t just “you import json-parser“, it’s “you call stream_parse(), set_date_format(), and on_error(skip).” The output is a usage fingerprint: a structured representation of your actual dependency surface.
Step 2: Build a candidate feature model. For each candidate alternative, construct a model of its API surface, what functions it exposes, what capabilities they provide, and how they map to common patterns. This can be derived from documentation, type signatures, README examples, and increasingly, LLM-based analysis of the library’s public interface. The key insight is that you don’t need to model the entire candidate library. You only need to model the subset that overlaps with your usage fingerprint.
Step 3: Compute feature overlap. Compare the usage fingerprint against each candidate’s feature model. The output is a compatibility score: what percentage of your required capabilities does this candidate cover, and which specific gaps exist? A candidate that covers 11 of your 12 required methods with equivalent APIs and has one gap you can work around is very different from one that covers 6 of 12.
Step 4: Estimate migration complexity. For the covered features, assess how similar the API shapes are. A method with the same signature and semantics is zero effort. A method with different parameter ordering is trivial. A fundamentally different approach to the same problem, say callback-based vs. streaming, is a significant rewrite. Static analysis of call sites combined with LLM-based reasoning about API documentation can produce a rough but useful migration effort estimate.
Step 5: Combine with trust scores and rank. Feed the compatibility score and migration effort estimate back into the trust score comparison framework. A candidate with 95% feature overlap, low migration effort, and a trust score of 8.5 is obviously preferable to one with 80% overlap, high migration effort, and a trust score of 7.0, even though both are better than your current component scoring 2.1.
This pipeline is tractable with today’s technology. Reachability analysis is mature. LLMs are genuinely good at reasoning about API documentation and method signatures. Knowledge graphs can model the relationships. What’s missing is the integration, the plumbing that connects these pieces into a coherent workflow.
The Evaluation Framework: Trust Score Comparison
Finding alternatives is only the first step. The second — and more important — step is evaluating them rigorously. This is where the trust scoring model from the previous article becomes the engine for decision-making.
For any candidate replacement, you want to compare:
| Criterion | Current Library | Candidate A | Candidate B |
|---|---|---|---|
| Direct trust score | 2.1 | 7.8 | 6.5 |
| Vulnerability frequency | 12/year | 2/year | 4/year |
| MTTR | 47 days | 8 days | 15 days |
| Open vulnerabilities | 7 | 0 | 1 |
| Maintenance health | Declining | Active | Active |
| Confidence level | 0.85 | 0.92 | 0.71 |
| License compatibility | MIT | MIT | Apache 2.0 |
| API compatibility | — | High | Medium |
But here’s where my concern arises — and where most “just swap the library” advice falls short. A trust score comparison alone isn’t enough. You also need to consider:
API compatibility. How much code do you need to change? A drop-in replacement is one thing. A library with a fundamentally different API shape is a multi-sprint migration project.
Transitive dependency impact. Does the replacement bring its own problematic dependencies? You could swap a low-trust JSON parser for a higher-trust one that happens to depend on a low-trust compression library. Check the candidate’s effective score, not just its direct score. This is exactly what the effective score propagation model is designed to catch.
Functional parity. Does the candidate actually cover all the features you’re using? A library might score beautifully on trust metrics but lack support for the specific edge case your application relies on.
Performance characteristics. Security isn’t the only dimension. If the replacement is 10x slower for your workload, that’s a non-starter regardless of its trust score.
License compatibility. A candidate with a copyleft license might score 9/10 on trust but be unusable in your proprietary codebase. Always check licence compatibility alongside trust scores.
The Cost-Benefit Calculation
Now let’s talk about the elephant in the room: effort.
Swapping a dependency isn’t free. There’s the engineering effort to migrate, the testing to validate, the risk of introducing regressions, and the opportunity cost of not building features. So how do you decide whether a swap is worth it?
This is where the monetary risk exposure from the previous article closes the loop. If you’ve associated asset values and data tier multipliers with your applications, you can quantify the risk reduction of a swap:
risk_reduction = risk_exposure_before − risk_exposure_after
Where each risk exposure is calculated from the effective trust score propagated through the graph. If replacing dodgy-json-parser (trust score 2.1) with solid-json-parser (trust score 7.8) improves the effective trust score of your payments application from 3.1 to 6.4, and that application processes £50M in annual transactions at data tier 1:
risk_before = 50,000,000 × (1 − 3.1/10) × 3.0 = £103,500,000
risk_after = 50,000,000 × (1 − 6.4/10) × 3.0 = £54,000,000
risk_reduction = £49,500,000

Now compare that risk reduction against the estimated engineering effort to migrate. Even if it takes a team two sprints — let’s say £50,000 in engineering cost — the risk-adjusted return on that investment is enormous.
Of course, risk exposure isn’t the same as expected loss. The numbers above represent potential exposure, not a guarantee of breach. But they give you and your leadership a way to compare apples to apples: the cost of the migration versus the reduction in quantified risk exposure. That’s a conversation a CISO can take to the board.
The Practical Playbook
So how would I recommend approaching this in practice?

Step 1: Triage by risk exposure. Start with the components that contribute most to your ecosystem’s risk. Sort your dependency graph nodes by their contribution to the effective score of your highest-value applications. The component dragging down the most business-critical applications gets attention first.
Step 2: Query for alternatives. For each target component, query LibHunt, libraries.io, and your package manager’s native search to build a candidate list. Cast a wide net — you’re looking for functional equivalents, not identical clones.
Step 3: Score the candidates. Run each candidate through the trust scoring pipeline. Compare direct scores, effective scores (including their transitive dependencies), vulnerability profiles, and maintenance health. Discard any candidate whose confidence level is below 0.5 — you don’t have enough data to trust the score.
Step 4: Assess migration cost. For the top candidates, estimate the migration effort. How different is the API? How many call sites exist in your codebase? Is there a migration guide or compatibility shim? This is where your engineering teams need to be involved — trust scores don’t tell you how hard the code changes will be.
Step 5: Rank by risk-adjusted ROI. Divide the risk reduction by the estimated migration cost. The components with the highest ratio are your best investments. Present these to leadership as a prioritised remediation backlog, in business terms.
Step 6: Migrate and validate. Execute the swap, run your test suites, monitor for regressions, and — this is the part people forget — verify that the effective trust scores have actually improved as expected. The propagation model should reflect the change automatically.
What Needs More Thought
I want to be honest about where this approach has gaps that need further work.
Building the feature-level pipeline is non-trivial. I’ve outlined what the ideal alternative discovery pipeline would look like, combining reachability analysis with LLM-based feature modelling and compatibility scoring. But I don’t want to understate the engineering effort involved. Reachability analysis outputs vary significantly across tools and ecosystems. LLM-based API surface modelling is promising but not yet reliable enough for fully automated decision-making, you’ll need human review in the loop, at least initially. And the “feature overlap” computation requires a semantic understanding of what functions do, not just what they’re called, which is a genuinely hard problem in its own right. This is solvable, but it’s not a weekend project.
Coverage will be uneven across ecosystems. The npm and PyPI ecosystems have rich metadata, active communities, and good tooling coverage, the feature-level pipeline will work best there first. But Cargo, NuGet, Maven, and especially niche ecosystems will lag. In some ecosystems, particularly for specialised or domain-specific libraries, there simply may not be a viable alternative, and you’re left with the uncomfortable choice between a low-trust component and building it yourself.
The “when to swap vs. when to contribute” question. Sometimes the right answer isn’t to swap the library, it’s to contribute fixes upstream. If a component scores poorly on security practices but has a responsive maintainer community, submitting PRs to enable branch protection, add SAST, or fix open vulnerabilities might improve the trust score for your entire ecosystem at a fraction of the migration cost. The evaluation framework should incorporate this option.
Multi-ecosystem complexity. Most real-world applications don’t live in a single package ecosystem. A Java application might depend on npm packages through a frontend build, Python packages through ML tooling, and Go binaries through infrastructure. The alternative discovery needs to work cross-ecosystem, which none of the current data sources handle particularly well.
The human factor. Engineers have preferences. They know certain libraries intimately. Telling a team to swap out a library they’ve used for five years, even with strong trust score data backing the decision, is a change management challenge as much as a technical one. The data makes the case, but you still need buy-in.
The Roadmap: SBOM-Graph Integration
For the roadmap of SBOM-Graph, the vision is to close this loop directly within the tool, and to do it at the feature level, not just the category level.
When a node in your dependency graph is flagged with a low trust score, the system should automatically surface suggested alternatives. But unlike a simple LibHunt or libraries.io lookup, these suggestions will be informed by your actual usage of the flagged component. The system will use the reachability data already present in the graph, which functions your codebase calls, which capabilities it depends on, to filter and rank candidates based on genuine feature overlap, not just category similarity.
Think of it as a recommendation engine for your dependency graph, but one that understands how you use your dependencies, not just that you use them. Instead of saying “here are five other JSON parsers,” it says “here are three JSON parsers that support the streaming deserialization and error recovery modes you depend on, ranked by trust score improvement and estimated migration effort.”
The pipeline I described earlier, extract usage fingerprint, build candidate feature models, compute overlap, estimate migration complexity, combine with trust scores, will run as part of the enrichment process when the graph is built or updated. When you view a low-trust node, the top alternatives appear right there in the graph view, complete with compatibility scores, projected trust score improvements, and the specific API gaps (if any) that would need to be addressed.
This capability will also be available as a standalone command-line tool, independent of the graph view. You should be able to point it at a specific package, say sbom-graph suggest-alternatives dodgy-json-parser --ecosystem npm, and get back a ranked list of alternatives with trust scores, feature overlap assessments, and migration effort estimates. This is important for two reasons. First, not every team will be using the full SBOM-Graph platform, but they should still be able to query for better alternatives to a problem dependency. Second, a CLI tool can be integrated into CI pipelines, automated remediation workflows, and policy engines, if a dependency drops below a trust score threshold, the pipeline can automatically generate a migration recommendation and attach it to a ticket.
The data flow works in both directions. The CLI queries the same data sources and scoring pipeline as the graph enrichment process. And the results can be fed back into the graph to enrich nodes with alternative metadata, so the graph view always reflects the latest recommendations. Whether you’re looking at the graph in a browser or running a query from a terminal, you get the same data-driven, feature-aware recommendations.

That’s the direction we’re heading. The category-level data sources, LibHunt, libraries.io, GitHub Topics, provide the initial candidate pool. The reachability data provides the usage fingerprint. LLMs provide the API surface reasoning. And the trust scoring model provides the ranking. What’s left is the integration to connect them, and honestly, the hard engineering work to make the feature-level matching reliable enough to trust at scale.
Final Thoughts
The reactive posture that most organisations take to supply-chain risk, wait for a CVE, scramble to patch, raise a waiver, move on, is expensive, stressful, and fundamentally inadequate. It treats symptoms while the underlying disease keeps spreading.
Proactive dependency swapping, guided by trust score data and prioritised by business risk, offers a way out. Yes, it requires upfront investment. Yes, it means convincing leadership that migrating away from a library before it causes a breach is a better use of engineering time than building features. But if you’ve done the risk exposure calculation and the numbers say the swap reduces £49M of risk for £50K of engineering effort, that’s not a hard sell.
The alternative is to keep fighting fires. And if there’s one thing I’ve learned from threat modelling dependency graphs, it’s that the fires only get more frequent.
Note to engineering leaders: Start with your three highest-value applications. Identify the single lowest-trust component in each of their dependency trees. Before you even search for alternatives, get your engineers to run reachability analysis and tell you exactly which APIs they’re calling in that library, that’s your usage fingerprint. Then query LibHunt and libraries.io for candidates, and filter them against that fingerprint. You’ll throw out half the list immediately because they don’t cover your actual usage, and what’s left will be genuinely viable. Score the survivors. Estimate the migration. Do the maths. I suspect you’ll find at least one swap that’s so obviously worth doing that the only question is why you haven’t done it already.
Stay tuned! Next I want to talk about Dependency Pruning or Tree Shaking and how we can use it to reduce the attack surface.
You may also like:

Threat Modeling Your Dependencies - Part 1
How One Bad Library Can Poison Your Entire...
Your SBOM Data Has Been Gathering Dust - Until Now
I’ve been talking about graphs for dependency analysis...

Is Your AI Philosophy Broken?
AI-Generated Code: Productivity Gains, Security Pains, and the...

Threat Modeling Remotely with Miro and EoP
Threat modeling with teams is a process that requires visuals, interaction between team members and discussion and so lends itself to everyone being in a room together. This has been quite hard the last two years. It also doesn’t look to be getting any easier, so we should probably get used to it. Here’s how I’ve been doing it with several teams.