Data Protection and Data Privacy - Part 2 of 2


From Principle to Practice: Privacy in the Real World
In Part 1 I worked through what personal data actually is, the full data lifecycle, the privacy principles, and Privacy by Design. That was the foundation. This post is about what you actually do with it.
Specifically, I want to cover eight things:
- How to threat model for privacy
- Privacy harms, objective and subjective, and why the distinction matters
- The dark patterns that violate the principles in plain sight
- Data subject rights and the engineering reality behind them
- The technical controls that matter (and the ones people get wrong)
- The data inventory and Records of Processing Activities
- AI, inference, and the privacy reckoning
- The ethical posture that should sit above all of it
By the end of this, an engineering architect should have a clear picture of where privacy gets implemented in their architecture, and an executive should have a clear picture of what it actually takes to behave ethically with data, not just claim to.
Let’s get into it.
Threat Modelling for Privacy
Most threat modelling people are familiar with is security-focused: STRIDE, attack trees, abuse cases, that family of approaches. STRIDE is excellent for confidentiality, integrity, and availability, but it doesn’t have anything to say about purpose limitation, consent, or inference on its own. Four families of approach close that gap: extending STRIDE itself (becoming STRIPED, often operationalised with Mark Vinkovits’ Privacy Suit for card-based EoP sessions); the LINDDUN academic framework from KU Leuven; T.R.I.M. (also known as Elevation of Privacy), the F-Secure team’s card-based privacy deck; and Elevation of Autonomy, the card deck I’ve been developing for agentic systems.
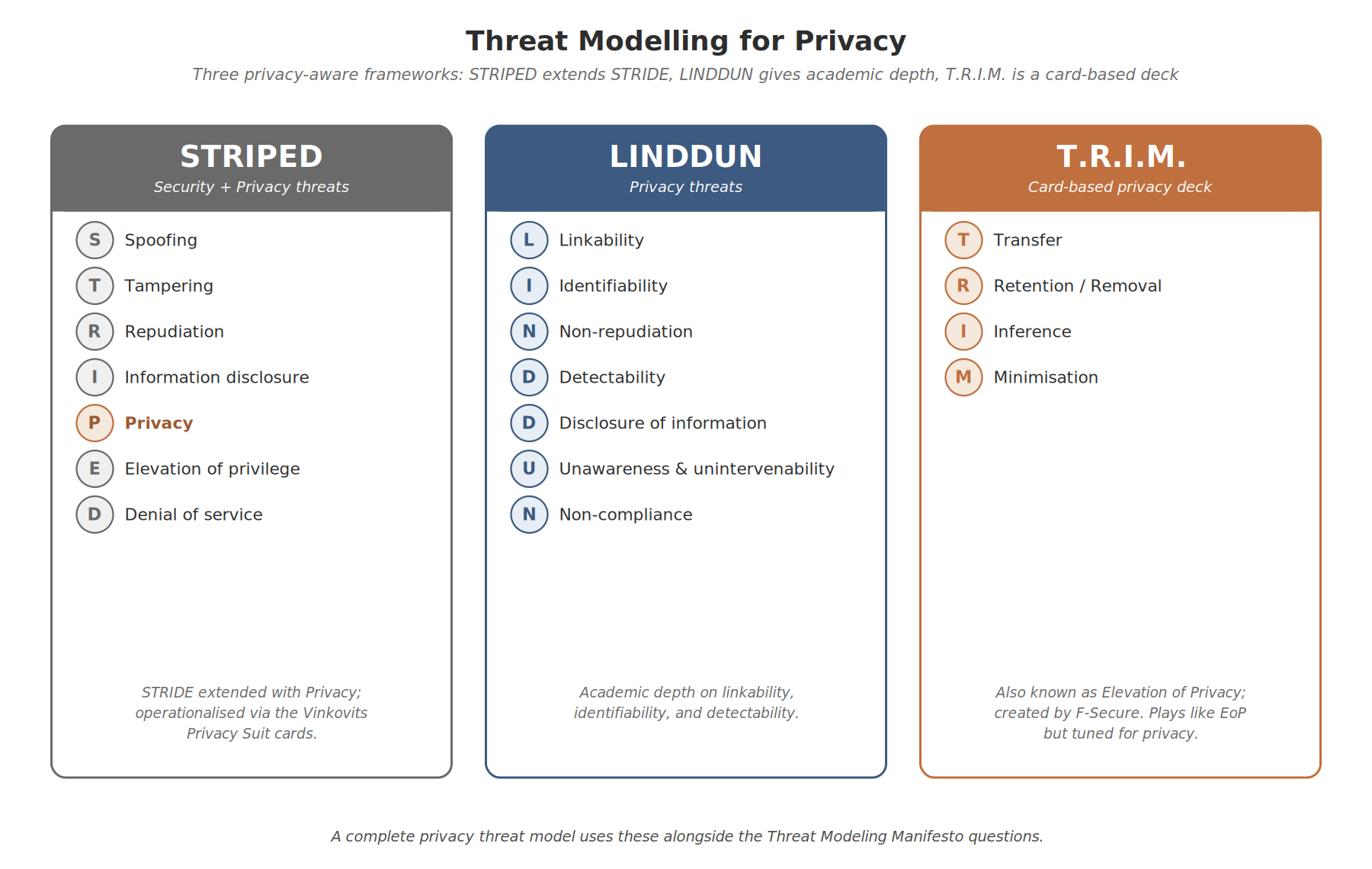
Extending STRIDE for Privacy: STRIPED and the Vinkovits Privacy Suit
The cleanest extension to STRIDE for privacy is to add Privacy as a category, giving you STRIPED: Spoofing, Tampering, Repudiation, Information disclosure, Privacy, Elevation of privilege, Denial of service. The Privacy category collects threats that don’t fit cleanly into the others: failure to handle consent withdrawal, retention beyond legitimate purpose, opaque processing, unauthorised secondary use, cross-border transfers without safeguards. STRIPED keeps the familiar STRIDE walkthrough but ensures privacy threats aren’t quietly dropped on the floor.
For teams already running Elevation of Privilege (EoP) threat modelling sessions, Mark Vinkovits’ Privacy Suit gives you the concrete card set to play through STRIPED’s Privacy category. The suit adds 13 cards (2 through Ace, like every other suit in the deck), each mapping to a specific privacy failure mode. The cards map cleanly onto the GDPR principles I covered in Part 1, and they overlap with LINDDUN in places (notably on linkability, identifiability, and disclosure), but for a team already comfortable with EoP, the Privacy Suit drops in with zero retraining and lets a single session cover both security and privacy threats. I cover this approach in detail in Threat Modeling Gameplay with EoP (Packt, 2024).
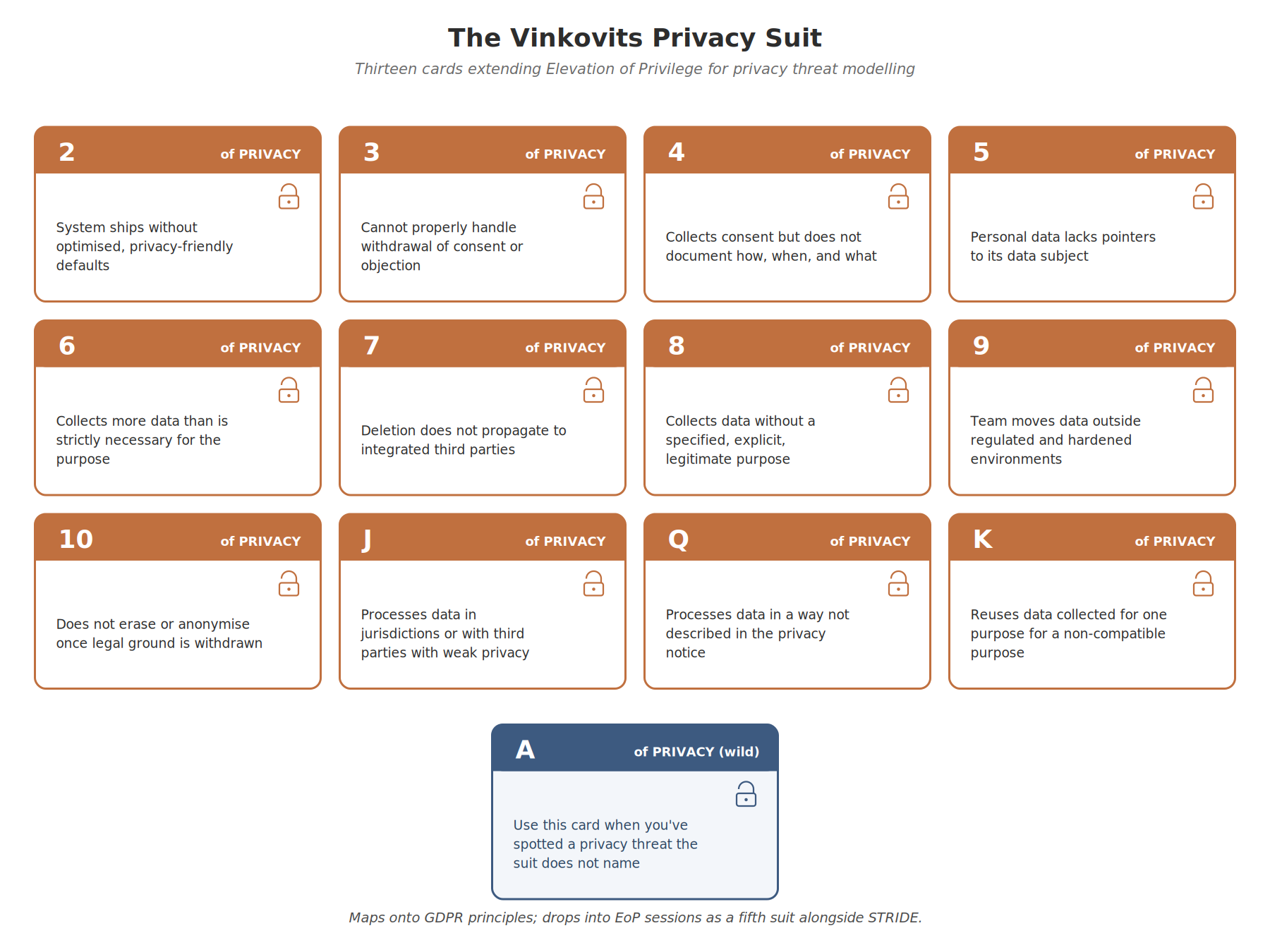
The point of the suit is not novelty but ergonomics. Threat modelling adoption fails most often because the activity feels foreign. The Privacy Suit lets a team that has already learned card-based threat modelling apply it to privacy in the same session, with the same tooling, with the same facilitation pattern.
Here are Mark’s descriptions for each of the cards in his Privacy suit he kindly shared with me:
2. Your system does not ship by default with optimized, privacy-friendly settings.**
When there are settings that a user can configure, for example to limit access to personal data, disable some processing - like analytics - or limit retention, then these settings should have the most privacy respecting default value. Alternatively, when choice is given to the user - for example like cookie banners, the most privacy-friendly setting should be as easy to configure as any other option.
3. Your system is not able to properly handle withdrawal of consent or objection to processing.**
Consent can be withdrawn when the particular processing activity needs to be stopped, separately from any other personal data processing happening. The system needs to be prepared to handle these scenarios without compromising functionality.
4. Your system collects consent but is not documenting aspects as to how, when, and to what consent was provided.**
The burden of proof that consent was given is with the system. Hence for processing, relying on opt-in consent, your system should persist the information that can later prove that the data subject did actually provide their consent.
5. Personal data in your system is missing pointers to data subjects, hence the data is forgotten when the owner is deleted or makes a request for access.**
Whenever you persist personal data you need to know how you’ll be able to discover who the personal data belongs to. This can result in non-compliance during the process of updating properties of a data subject where the previous information is not deleted as part of the update.
6. Your system collects more personal data than strictly necessary to fulfill the intended purpose.**
Think of what personal data is the bare minimum to make your functionality work. For everything else, you should make it clear to the data subjects that the information is optional to provide (and hence processing is likely based on consent, see 4.)
7. Your system is not following through on personal data deletion in integrated 3rd parties.**
If you use 3rd parties as sub-processors, then the requirement of ensuring proper data retention is clearly with your system. Even if it is a joint-controllership, whenever obliged to delete personal data, you should highlight to data subjects that their data may be sitting with other 3rd parties as well.
8. Your system is collecting personal data without being able to name the specified, explicit and legitimate purpose it is used for.**
For all personal data in the system you should be able to name how it got there and why exactly it is needed. If you cannot, you should probably not have it in the system at all. This is a bit broader version of 6 just without any initial legitimate purpose.
9. Your product team avoids the existing and prescribed controls for personal data by copying personal data out of the regulated and hardened environments.**
If “someone outside your operations team asks for a one-time export of a database containing personal data” sounds familiar, then this card probably applies to your system. How are such exports handled later in their lifecycle? To put it differently, wherever personal data is stored, it needs to meet all the company policies for personal data, hence do not send it around in emails, store it in cloud drives, etc unless that is covered by your policies.
10. Your system does not implement erasure or anonymization for personal data once the legal ground for processing has been withdrawn.**
For all personal data you should be able to name an event when that personal data is deleted/anonymized, either a defined schedule or a particular event in the lifecycle. If you are missing that, you are at risk for storing personal data longer than necessary to fulfill its original purpose.
J. Your system is processing personal data in countries or with 3rd parties which have weak privacy standards.**
There are strict requirements around personal data transfers. Were all integrated 3rd parties who receive personal data properly screened in terms of protections they provide and legislation they follow? This needs to be particularly well documented where personal data is being transferred to a different country.
Q. Your system is processing personal data in a way that is not described in the privacy notice or is unexpected to the data subjects.
All personal data processing that happens needs to be transparent to the participants of the system and be clearly highlighted in the UI and privacy notice. If there might be processing that would surprise participants of the system, you are likely at risk.
K. Your system reuses personal data collected for a specific purpose for a non-compatible other purpose.
Only because you already have some personal data, doesn’t mean you can use it for whatever purpose you want. Always think of personal data in terms of tuples: <personal data used, purpose used for>. If you change any parameter in the tuple, that is considered a new type of processing and will need its own legal basis and due diligence to happen before started.
LINDDUN
LINDDUN, developed by Kim Wuyts and colleagues at KU Leuven, is the most established privacy threat modelling framework. The acronym covers seven categories: Linkability, Identifiability, Non-repudiation, Detectability, Disclosure of information, Unawareness and unintervenability, and Non-compliance. It works very much like STRIDE: you walk through your data flow diagrams and ask, for each element, which of the seven categories of threat might apply.
What makes LINDDUN powerful is that it catches privacy threats that don’t show up in STRIDE. A perfectly secure system (no spoofing, no tampering, no information disclosure to unauthorised parties) can still be a privacy disaster if it makes records linkable across contexts, identifies users who expected to be anonymous, or makes activities detectable that users wanted hidden.
T.R.I.M. (Elevation of Privacy)
T.R.I.M., also known as Elevation of Privacy, is a card-based privacy threat modelling deck created by a team at F-Secure (Marko Hämäläinen, Laura Noukka, Hiski Ruhanen, Ilona Varis, and Antti Vähä-Sipilä). It plays the same way as Elevation of Privilege but the suits are tuned for privacy threats specifically. The four suits are:
- Transfer: data being transferred around the world (cross-border flows, third-party processors, jurisdictional risk)
- Retention / Removal: data retained only for as long as the purpose requires or the law mandates (and properly removed thereafter)
- Inference: connecting the dots between existing data to derive additional data the subject never gave you (the threat I called out in Part 1 with the pregnancy and depression examples)
- Minimisation: collecting only the data needed for the job at hand (the principle Compute and Discard, which I cover later in this post, operationalises)
T.R.I.M. is general privacy, not AI-specific. But its Inference suit is the one that maps most usefully onto AI and ML systems, because trained models are inference engines whether or not the data subject understood that when they handed over their data. I’ll come back to that thread in the AI section later in this post.
Elevation of Autonomy
The three frameworks above each have their strengths, but none of them was built with agentic AI systems as the design centre. Elevation of Autonomy (EoA) is a card-based threat modelling game I’ve been developing specifically for that gap. T.R.I.M., LINDDUN, and the Vinkovits Privacy Suit were all inspirations for the card set, but EoA isn’t a privacy framework dressed in agentic clothing: privacy threats sit in the deck alongside agency, autonomy, and inference threats rather than as a bolt-on category.
The deck itself is still being finalised, but the Elevation of Autonomy repository already contains worked examples that walk through privacy threats for AI and agentic scenarios. If you’re building anything where a model is making consequential decisions about humans without a human in the loop for each one, those examples are a practical entry point today.
Beyond STRIPED, LINDDUN, T.R.I.M., and EoA
These four are starting points, not the whole picture. A proper privacy threat model also incorporates the four questions from the Threat Modeling Manifesto (“what are we working on?”, “what could go wrong?”, “what are we going to do about it?”, “did we do a good enough job?”), specific regulatory threats from GDPR, NIS2, the EU AI Act, and the UK Data (Use and Access) Act, and ethical threats that go beyond what’s legally required. I’ll be covering a more comprehensive privacy threat modelling approach in a future post. For now: use STRIPED with the Vinkovits Privacy Suit when your team already runs card-based EoP sessions, reach for LINDDUN when you need broader academic coverage, pick up T.R.I.M. when you want a standalone privacy deck (especially when transfer, retention, and inference threats dominate your data flows), and use Elevation of Autonomy when you’re modelling agentic systems where autonomy itself is part of the threat picture.
Privacy Harms: Objective and Subjective
Threat modelling tells you what could go wrong. But what does “wrong” actually mean? When privacy fails, what happens to the data subject?
Ryan Calo’s 2011 paper The Boundaries of Privacy Harm set out the modern distinction. Privacy harms divide into the objective (the unanticipated or coerced use of information against a person) and the subjective (the perception of unwanted observation, even where no specific use is yet known). Both engineers and executives need to understand the distinction, because the law has caught up with both categories and because the way you scope a threat model depends heavily on which kind of harm you weight.

Objective Harms
These are the tangible, observable consequences. They can be pointed to and counted:
- Financial loss: fraud, identity theft, account takeover, unauthorised transactions
- Physical harm: stalking, doxxing leading to violence, location data exposed to abusers
- Discrimination: denied a job, loan, mortgage, insurance, or housing because of profile data
- Loss of opportunity: excluded from services, employment pools, or marketing reach
- Loss of liberty: wrongful arrest or detention based on biased automated decisions
These are the harms that courts have historically recognised because they show up in a record or on a balance sheet.
Subjective Harms
These are the felt consequences. They don’t appear in financial accounts but they are no less real:
- Anxiety and distress about how data is being used or who might see it
- Loss of dignity, particularly when private matters are exposed
- Loss of autonomy when decisions are made on someone’s behalf without their knowledge
- Chilling effects on speech, association, and behaviour: people change what they do because they feel watched
- Loss of trust in the institutions that hold their data, and the powerlessness that comes with it
GDPR Article 82 explicitly allows compensation for both material (objective) and non-material (subjective) damage. UK case law has been catching up: Vidal-Hall v Google established that distress alone is a compensable harm under UK data protection law. Subjective harms are now firmly inside the scope of regulatory and civil remedy.
Why The Distinction Matters in Practice
Two reasons.
First, when you scope a privacy threat model, asking “what’s the worst that can happen?” too often defaults to objective harms because they are easier to articulate in a meeting. A breach of stalking-victim location data might cause no measurable financial loss but it could cost a life. A leak of someone’s HIV status might trigger no fraud but devastate them. Your threat model needs to weight both.
Second, when something does go wrong, your incident response and customer communications need to acknowledge both. Saying “no fraud occurred, so no harm done” is a hostile message to people whose anxiety and loss of trust are themselves the harm. It is also legally inaccurate.
Daniel Solove and Danielle Citron’s 2022 paper Privacy Harms builds on Calo’s foundation with a more granular taxonomy. Calo (2011) is the foundational reference; Solove and Citron (2022) give you the academic depth. For practitioners, the working definition is simpler: a harm is what the affected person experiences, not what your lawyers can quantify.
Privacy Dark Patterns: Named and Shamed
The privacy principles from Part 1 are violated, daily and at scale, by design patterns that the industry has normalised. The OECD has documented these. The European Data Protection Board has issued guidance on them. They are not edge cases. They are the default behaviour of most consumer-facing software.

Let me name the patterns. If you’ve used the internet in the last decade, you’ve seen all of these.
Confirmshaming
The “no thanks” option is worded to make the user feel stupid or guilty for declining. “No, I don’t want to save money.” “No, I prefer to pay more for shipping.” The wording isn’t about choice, it’s about manipulation.
Roach Motel
Easy to get in, hard to get out. Signing up is one click. Unsubscribing requires navigating through three settings menus, confirming via email, and waiting 48 hours. The same pattern shows up in subscription flows where auto-renewal is the default, the cancellation path is buried, and “pause your subscription” is offered as a euphemism that obscures what’s actually happening (you might think you can pause a 12-month subscription at month 6 and resume it later; in practice you’ve just agreed to keep paying). The privacy angle is that purpose limitation quietly stretches with the data: you consented to processing for one period of service, and now it continues, often into different processing activities you didn’t sign up for.
Privacy Zuckering
The user is tricked into sharing more data than they intended through deliberately confusing settings, vague language, or pre-selected options that override their stated preferences. The term is widely used in dark patterns research literature.
Forced Enrolment
The user can’t access the service without consenting to data collection that isn’t necessary for the service itself. Under GDPR, consent given under coercion is not valid consent. The practice persists because enforcement is patchy.
Inverted Button Hierarchy
The “accept all cookies” button is large, bright, and prominent. The “reject” or “manage preferences” option is small, grey, or hidden under “options”. The visual hierarchy is doing the work that the words can’t openly do.
Pre-ticked Consent Boxes
Explicitly outlawed under GDPR Article 7 and confirmed by the Planet49 CJEU ruling, but still common in practice. If consent is the default, it’s not consent.
Bundled Consent
“Click here to agree to our terms, privacy policy, cookies, marketing communications, third-party data sharing, and the use of your data for AI model training.” A single button collapsing multiple distinct consents into one, removing the granularity the law requires.
Hard-to-Find Opt-Out
The opt-out exists, technically, in a settings menu six clicks deep, behind a tab labelled something other than “privacy” or “data”. The user is theoretically empowered. Practically, they’ll never find it.
Misleading Defaults
The default settings maximise data collection. The user has to actively configure their way to a private baseline. This is the inverse of Privacy by Design’s “Privacy as the Default Setting” principle, and it’s the default of most consumer apps.
Click Fatigue
Make the user click “decline” individually on dozens of “partners” while “accept all” requires one click. The user gives up. The data flows.
These patterns work because they exploit cognitive load, time pressure, and the asymmetry between what users know they’re agreeing to and what they’re actually agreeing to. They are not technical failures. They are design choices made by people who knew exactly what they were doing.
Data Subject Rights: The Engineering Reality
The privacy principles give users specific rights over their data. Under UK GDPR and EU GDPR, these include:

Right of Access (Subject Access Request, or DSAR)
The user can request a copy of all personal data you hold about them. You have one month to respond. This sounds simple. It is not. To answer a DSAR properly, you need to know every system, database, log, cache, archive, and third-party processor that holds data about the user. If your data inventory is incomplete (and most are), you’re missing data in your responses, which is itself a compliance failure.
Right to Rectification
The user can require you to correct inaccurate data. Across all systems. Including downstream copies and derived data.
Right to Erasure (“Right to be Forgotten”)
The user can require deletion of their data when certain conditions are met. This must propagate through your entire estate: backups, replicas, caches, search indexes, analytics aggregates, and third-party processors. If a user requests erasure and your nightly backup still has them, you haven’t erased them. The engineering implications of this single right are enormous and routinely underestimated.
Right to Restriction
The user can require you to stop processing their data while a dispute is resolved. Your systems need a way to flag and quarantine a specific subject’s data, which most architectures don’t support natively.
Right to Data Portability
The user can require a machine-readable copy of their data for transfer to another provider. The format must be commonly used and structured. JSON or CSV is fine, but only if it actually contains all their data.
Right to Object
The user can object to processing based on legitimate interests, direct marketing, or scientific or historical research. Direct marketing objections are absolute: the user wins, full stop.
Rights Around Automated Decision-Making
Under Article 22, users have the right not to be subject to a decision based solely on automated processing that produces legal or similarly significant effects. With the rise of AI-driven decisioning, this right is becoming central to a host of disputes. The EU AI Act adds a further layer of obligations on top of this for high-risk AI systems.
Here’s where this connects back to everything I’ve written across the previous series: you cannot fulfil any of these rights without a complete and accurate data inventory. And if your inventory doesn’t capture data flowing through third-party libraries, your supply chain is undermining your privacy posture in ways you can’t see.
Technical Controls That Actually Work
Let me cover the controls that matter, with practical examples and worked scenarios.
Compute and Discard: Store the Answer, Not the Data
Before reaching for pseudonymisation, anonymisation, or any cryptographic trick, ask the simpler question: do you need to store the raw data at all?
A surprising number of access decisions can be made on a derived value rather than on the underlying personal data, and the derived value carries far less privacy risk. This is data minimisation in its most direct form: not just collecting less, but computing the answer at the point of collection and not retaining the source.
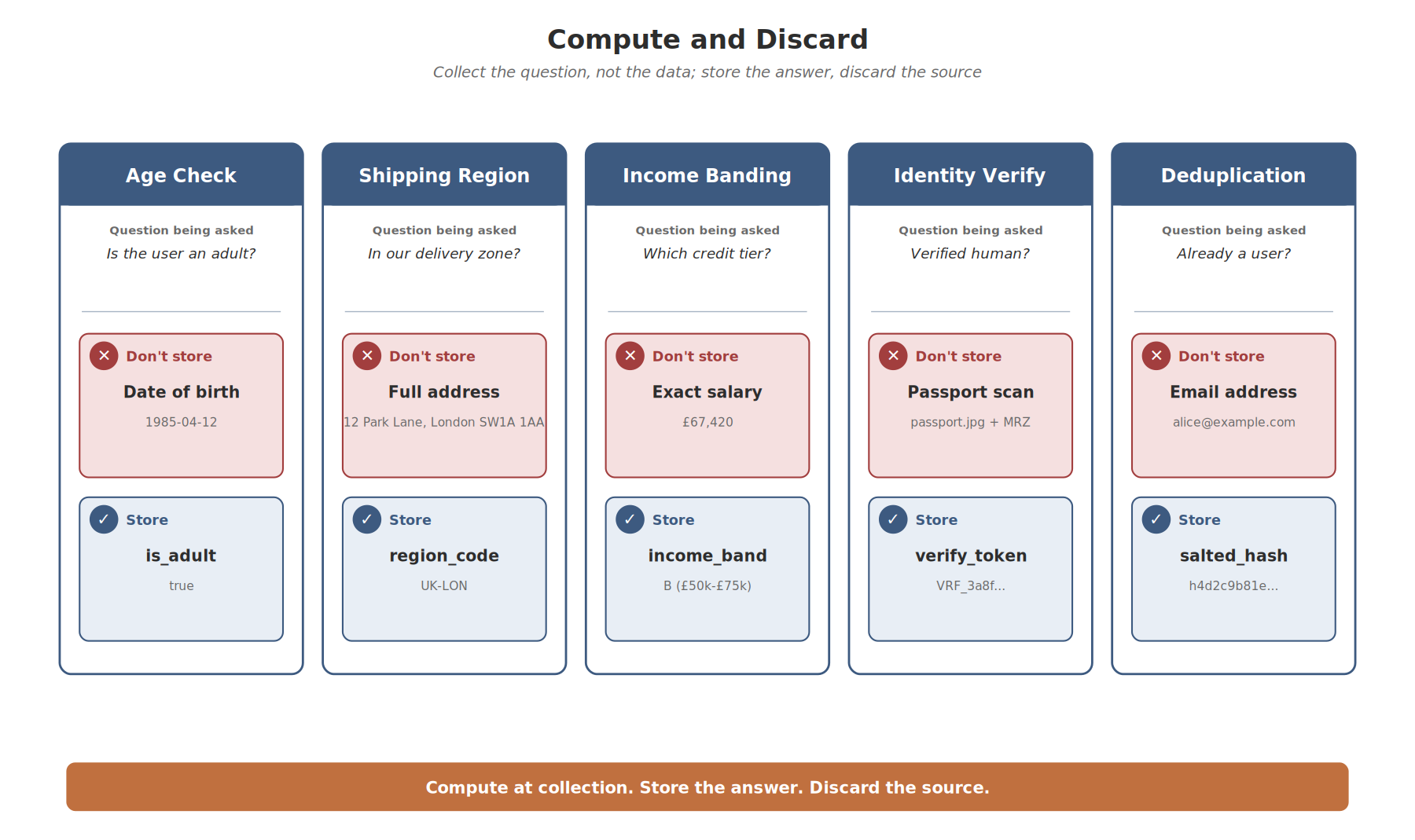
Worked examples:
- Age verification: you need to know whether a user is an adult. Compute
is_adultat verification time and store the boolean. Discard the date of birth. The question is answered; the source data is gone. - Shipping region: you need to know whether a customer is inside your shipping area. Store a region code or postcode prefix. The full address need not be retained after the verification step.
- Income banding: you need to assess income for credit risk. Store a banded income range, not the exact salary. The model performs nearly as well, and the disclosure risk falls significantly.
- Identity verification: use a tokenised reference returned from a verification service. The underlying ID document never has to enter your systems.
- Deduplication: you want to detect duplicate users without storing email addresses. Store a salted hash of the normalised email. You can check for collisions without being able to read the inputs.
This approach goes by several names in the literature: selective disclosure, minimal disclosure, predicate proofs, derived attributes. The underlying principle is the same. Collect the question, not the data. W3C Verifiable Credentials and emerging standards like Selective Disclosure JWTs (SD-JWT) are formalising this approach for digital identity, but the core idea works without any new technology. Compute the answer at collection, store the answer, discard the source.
Where this gets harder is when you genuinely need to recompute the derived value later. A user crosses an age threshold. They move house. Their income changes. In those cases the trade-off is between holding more data and accepting recomputation friction. The right answer is rarely “hold everything just in case”. The right answer is usually a refresh policy: re-verify periodically or at known life events, rather than holding raw data continuously.
This is the most underused privacy-enhancing technique in industry. It requires no new cryptography, no new vendor, and no new compliance investment. What it requires is the discipline to ask, at design time, whether your system needs the data or just the answer.
Pseudonymisation versus Anonymisation
This is the distinction most engineers get wrong, and it has serious legal consequences.

Pseudonymisation replaces direct identifiers with a token, but the mapping between token and identity is retained somewhere. If you can reverse the process given the right key, it’s pseudonymisation. Worked example: replacing user IDs in your analytics database with hashed tokens, while keeping the lookup table in your primary database. Pseudonymised data is still personal data under GDPR. It gets you reduced risk and some regulatory benefits (it’s a recognised security measure under Article 32) but it does not put the data outside the scope of the law.
Anonymisation removes identifiability irreversibly. There must be no realistic way to re-identify the subject, even by combining the data with other available datasets. True anonymisation is genuinely hard. Sweeney’s 87% result from Part 1 shows just how easily “anonymised” data gets re-identified through quasi-identifier composition.
Worked example: an analytics pipeline strips email addresses but retains IP address, user agent string, timezone, and behavioural sequence. The team calls this “anonymised”. It isn’t. With enough behavioural data and any one other source, the subjects can typically be re-identified. To genuinely anonymise, you’d need to apply k-anonymity (every record indistinguishable from at least k-1 others on quasi-identifiers), l-diversity, or differential privacy on top, and accept some loss of analytical utility as the price.
Differential Privacy
A formal mathematical definition of privacy that adds calibrated noise to query results so that the presence or absence of any single individual cannot be detected. Apple, Google, and the US Census Bureau all use variants of differential privacy in production. The trade-off is utility for privacy: the more privacy you guarantee (smaller epsilon), the noisier your results.
For practitioners: differential privacy is overkill for most operational data but appropriate when releasing statistical outputs derived from sensitive data, or when allowing third parties to query a dataset without exposing individual records.
Encryption: In Transit, At Rest, In Use
Encryption in transit (TLS 1.3, soon with post-quantum hybrid key exchange) and at rest (AES-256, with crypto-agility for the PQC transition I covered in the last series) are baseline. What most teams underinvest in is encryption in use: keeping data encrypted while it’s being processed. Homomorphic encryption, secure enclaves (Intel SGX, AMD SEV, AWS Nitro Enclaves), and confidential computing approaches are increasingly viable for the scenarios that matter.
The link back to PQC readiness is direct: today’s encrypted PII becomes tomorrow’s plaintext if it’s encrypted with algorithms that are broken by a cryptographically relevant quantum computer. Personal data, especially health data and genetic data, typically has retention periods that extend well beyond plausible quantum timelines. Harvest now, decrypt later is a privacy threat, not just a security one.
Access Control Patterns
Apply attribute-based access control (ABAC) for personal data, not just role-based. A doctor can see patients, but only their own patients. A support agent can see customer data, but only for the customer they’re currently helping. Purpose limitation gets enforced through access control, not just through policy documents. Every access request should specify what purpose it serves, and that purpose must match what was consented to.
The Supply Chain Connection
Recall the dependency graph from the supply chain series. A logging library at depth 3 in your dependency graph that helpfully captures full HTTP request bodies into log files is a privacy disaster. A JSON serialisation library that doesn’t handle unicode normalisation correctly might cause PII to leak through error messages. A monitoring SDK might phone home with detailed telemetry that includes personal data.
Personal data flows through every dependency you ship. The supply chain trust scoring model applies directly: a low-trust dependency in a privacy-critical path is not just a security risk, it’s a privacy risk. The same effective score, the same minimum-path score, the same business impact calculation, viewed through the privacy lens.
The Data Inventory
In my previous two-part series on getting Post Quantum Cryptography ready, I talked about the need for a data inventory and a cryptographic primitive inventory. They are both relevant here. The data inventory underpins data protection and privacy alike, and the cryptographic primitive inventory tells you whether the protection is actually current.
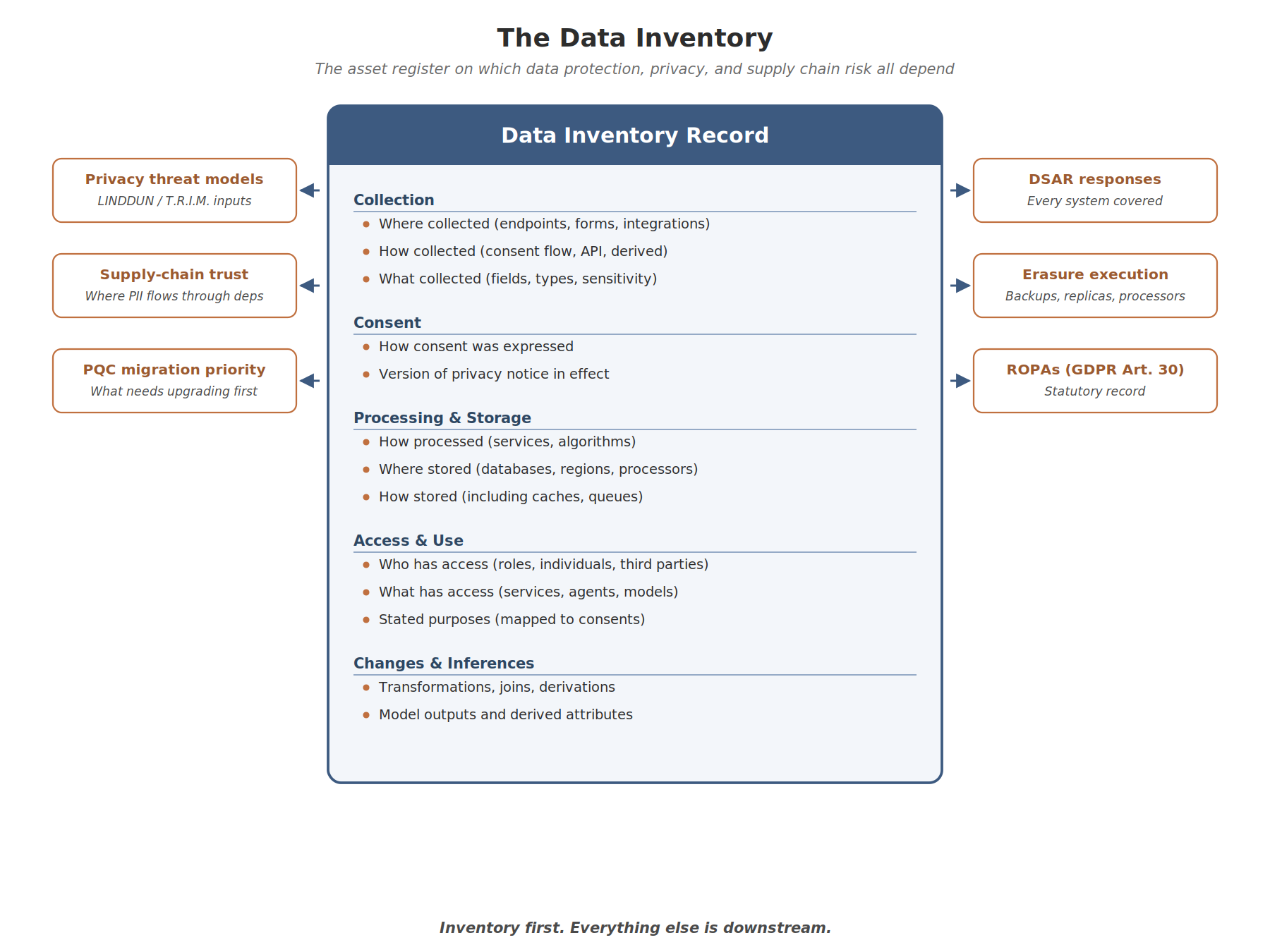
The inventory should not only catalogue data in your existing storage. It should also contain information gathered from source code (and, increasingly, from dependency analysis) that tells you:
- Where the data is collected (which endpoints, forms, integrations)
- How it is collected (consent flow, API ingestion, derived from other data)
- What is collected (specific fields, types, sensitivity classification)
- How consent was expressed (active opt-in, contractual, implied, none)
- The version of the privacy notice in effect when consent was expressed
- How it is processed (in what services, with what algorithms)
- How it is stored, even temporarily (caches, queues, in-memory state)
- Where it is stored (databases, file storage, third-party processors, regions)
- What it is being used for (specific stated purposes, mapped to consents)
- Who has access to it (roles, individuals, third parties)
- What has access to it (services, agents, models, APIs)
- What changes are made (transformations, joins, derivations)
- What inferences are made (model outputs, derived attributes)
With this information you can build Records of Processing Activities (ROPAs) for your internally developed applications, as required under GDPR Article 30. You’ll still need to cover third-party applications separately, but at least your own house is in order. And critically, you can build automated alerts that flag when new applications or features process data in ways that don’t match your declared purposes.
The data inventory is the asset register on which everything else depends. Trust scoring for supply chain risk. Data protection impact assessments. DSAR responses. Right to erasure execution. PQC migration prioritisation. Privacy threat modelling. All of it requires you to know what data you have, where it is, and what it’s being used for.
If you take only one thing from these two posts, take this: inventory first, everything else second.
AI, Inference, and the Privacy Reckoning
Everything covered up to this point becomes harder, and more urgent, when AI enters the picture. Statistical models infer, predict, and act on personal data in ways the privacy principles were not originally designed to constrain. The EU AI Act, in force since August 2024 with phased application through 2027, is the first attempt to regulate this systematically. It does not replace GDPR. It sits on top of it.
The Transparency Problem
GDPR requires processing to be transparent. The data subject should know what’s being done with their data. But how do you explain a model whose decision boundary nobody, including its creators, can articulate in plain English?
The legal answer is that controllers must provide “meaningful information about the logic involved”, not the model weights themselves. “Meaningful” is doing a lot of work in that sentence. A user denied a loan by an automated underwriting model has a right to know why. “The model said no” is not a meaningful explanation. Neither, in most cases, is a list of feature importances the user can’t act on. Most organisations deploying AI today are sitting in this transparency gap whether they realise it or not.
Automated Decision-Making Under Article 22 and the EU AI Act
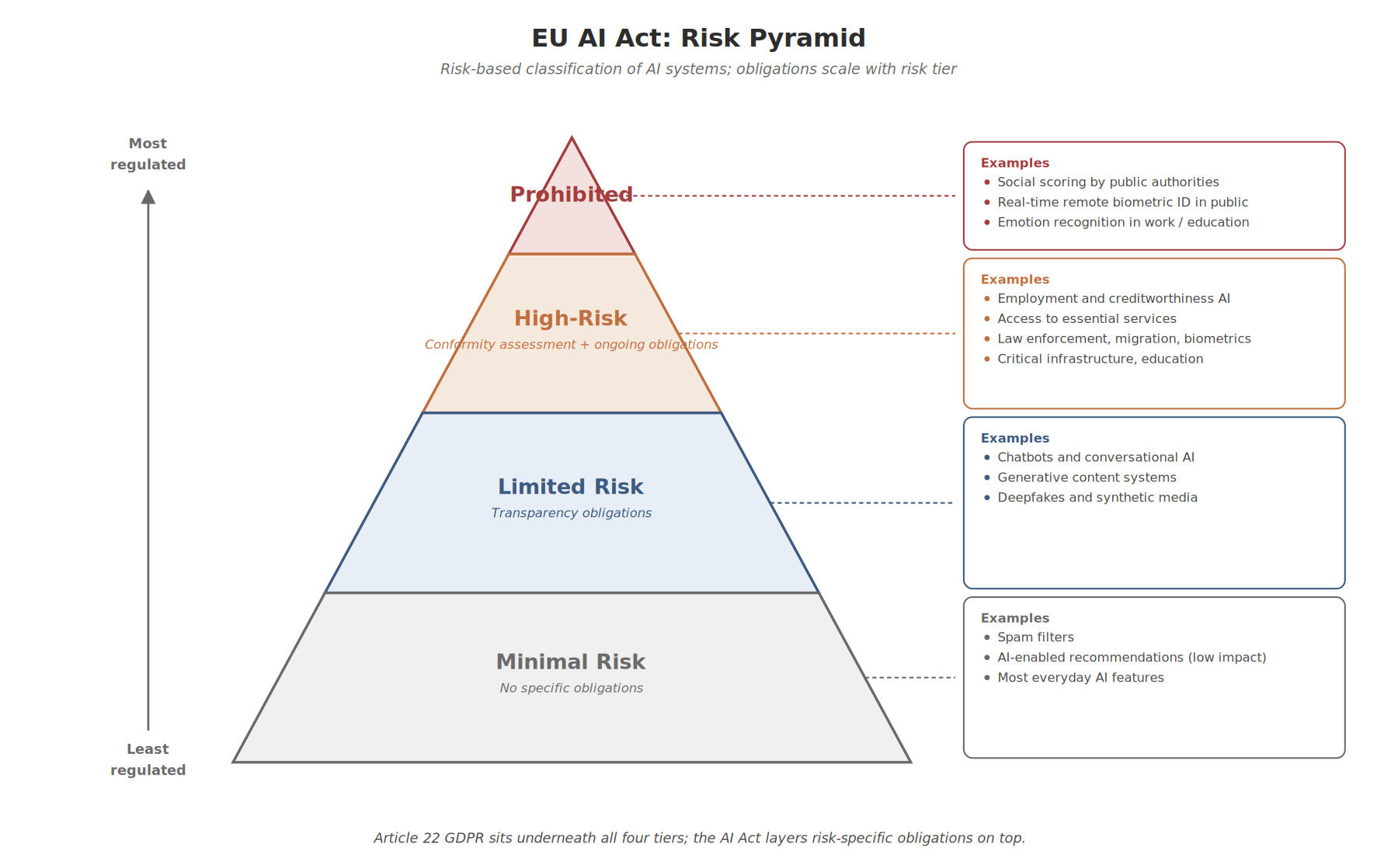
Article 22 of the UK and EU GDPR gives the data subject the right not to be subject to a decision based solely on automated processing that produces legal or similarly significant effects. The EU AI Act layers a risk-based classification on top of this baseline:
- Prohibited practices (Article 5): social scoring by public authorities, real-time remote biometric identification in public spaces (with narrow exceptions), emotion recognition in the workplace and education, manipulative AI exploiting vulnerabilities, untargeted scraping of facial images.
- High-risk systems (Annex III): AI used in employment, creditworthiness, access to essential services, law enforcement, migration, education, biometrics, and critical infrastructure. These require conformity assessments, risk management systems, data governance, human oversight, and registration.
- Limited-risk systems: transparency obligations apply (chatbots must identify themselves as AI, generated content must be labelled).
- Minimal-risk systems: no specific obligations.
If you’re building or deploying anything that automates decisions about humans, this categorisation is now a first-order architectural concern, not a compliance afterthought. It affects what controls you must build in, what documentation you must maintain, and what consequences attach when things go wrong.
Bias: A Privacy Problem We Don’t Usually Frame as One
Bias in AI is commonly framed as a fairness issue. It is. But it’s also a privacy issue, and we should frame it that way more often.
Here’s why. Bias in models comes from training data. Training data reflects historical patterns, many of which encode discrimination. When a model trained on biased data is used to make decisions about real people, it propagates that discrimination at scale. The data subject is being processed not just on their own data, but on inferred attributes drawn from patterns in everyone else’s data. Their treatment is shaped by what the model has decided people “like them” tend to do.
That isn’t fair, it isn’t transparent, and it isn’t respectful of individual rights. It’s a privacy problem wearing a fairness costume, and the mitigations require both engineering rigour (representative training data, bias testing, ongoing monitoring) and structural commitments (human oversight, the right to contest, honest documentation of known limitations).
Inference and Extraction Attacks
In Part 1 I noted that inferred data is personal data. AI systems infer at an industrial scale, and the inferences themselves create new privacy threats:
- Inference at scale: every model prediction about a person is personal data subject to their rights. Logging model outputs, versioning them, mapping them back to subjects, and being able to surface them on a DSAR is a first-class engineering requirement now, not a nice-to-have.
- Membership inference attacks: determining whether a specific record was part of a model’s training set. For a medical model, confirming someone’s data was in a diabetes-prediction training set is itself a disclosure of health information.
- Training data extraction: research has shown that large language models can be coaxed into regurgitating identifiable training data, including names, phone numbers, and email addresses embedded in their training corpora.
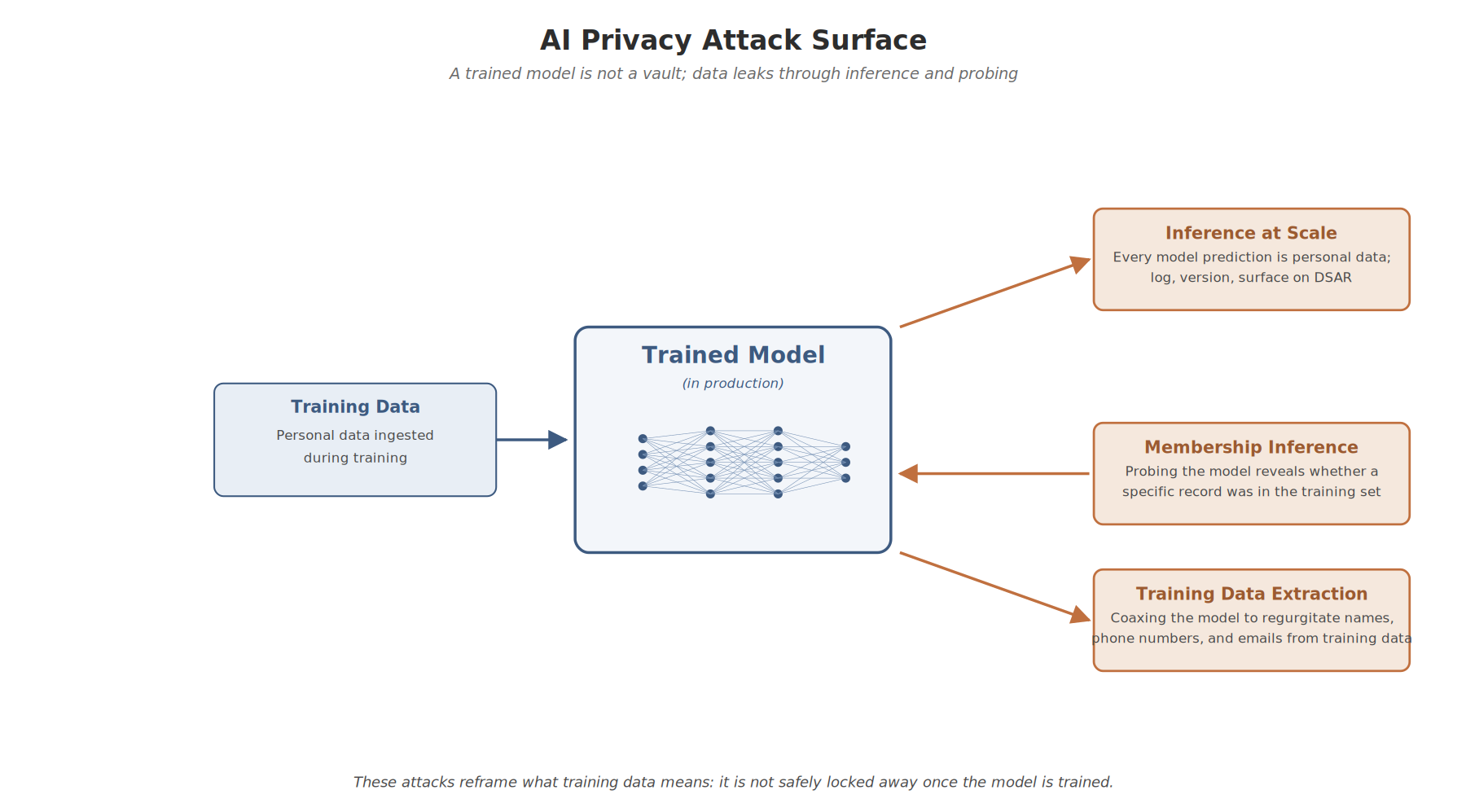
These attacks reframe what “training data” means. It is not safely locked away once the model is trained. It can leak through the model itself.
The Right to Erasure Meets the Trained Model
If a user exercises the right to erasure, you must delete their personal data. What does that mean when their data was used to train a model that is now serving production traffic?
The honest answer is that we don’t have a fully satisfactory solution yet. “Machine unlearning” research is active but immature. Retraining models from scratch when individual subjects request erasure is prohibitively expensive at any meaningful scale. Differential privacy in training (where each subject contributes only a bounded amount to the model) offers some protection but it is not a silver bullet.
For now, the pragmatic approach is to design with eventual erasure in mind, prefer architectures that can be retrained efficiently, treat training data with the same lifecycle discipline as operational data, and be honest with users and regulators about where the limitations sit.
Connecting Back to Elevation of Autonomy
This is the picture that Elevation of Autonomy exists to address. When an autonomous agent makes decisions, the privacy stakes compound. The agent infers, acts, propagates data, and accumulates context. Every threat I’ve outlined above applies, but with an additional twist: the human is no longer in the loop for individual decisions.
Treat any agent that processes personal data without per-decision human review as a high-risk system in the EU AI Act sense, and design accordingly. The EoA worked examples I pointed to in the threat modelling section are the practical entry point if you want to do this rigorously today.
Values, Ethics, and What Executives Actually Need to Do
I’ve kept the ethics for last because it doesn’t belong in a section, it belongs as the frame for everything else.

When you collect someone’s data, hiding the details in a 2,000-word essay called a privacy notice that nobody will ever read is not telling them what you’ll use it for. It’s hiding it in a way the law permits. That doesn’t make it ethical or justifiable.
Making the button to refuse cookies not work, or buried, or so visually de-emphasised it might as well not exist, while the button to accept them is large and prominent: that is not user choice. That is driving customers to click out of sheer exasperation. It’s rude, disrespectful, and corrosive of the trust that makes commerce possible.
Tracking people across services and devices in order to build behavioural profiles they didn’t ask for, with the data sold or shared with parties they never heard of, while claiming the user “consented” because they didn’t notice the dark pattern: that is not consent. It’s the manufactured appearance of consent. Calling it consent doesn’t make it consent any more than calling a shop assistant a financial advisor makes them a financial advisor.
And here’s the part that should land hardest for any executive reading this.
Most organisations have a values page. “We respect our customers.” “We put people first.” “Trust is at the heart of what we do.” These are claims. Claims are cheap. The cookie banner on your website, the consent flow in your mobile app, the data sharing relationships with your ad-tech partners, the retention period for your analytics data: these are evidence. And in most organisations, the evidence directly contradicts the claims.
If your stated values and your actual product behaviour disagree, your stated values are not values. They are marketing.
The way you fix this is not through more values statements. It’s through:
- Making the data inventory complete and current
- Collecting only what the stated purpose actually requires (not what might be useful one day)
- Running privacy threat models alongside security threat models
- Auditing your consent flows against the dark patterns catalogue and removing every one you find
- Aligning your retention periods with actual business need, not legal maximum
- Making your privacy notice readable by a human in under two minutes
- Defaulting to privacy and making the opt-in the active choice
- Treating data subject rights as a first-class engineering concern, not a compliance afterthought
- Holding your supply chain to the same privacy standard you claim to hold yourself to
Note to engineering leaders and executives: values are revealed in defaults, not declarations. Your defaults are the most honest thing your organisation says about itself. If your default is to maximise data collection, hide opt-outs, and require active resistance from users to maintain their privacy, your organisation has chosen a posture. Don’t dress that posture up as anything else. Either change the defaults or own what they say about you. Customers will work out which it is, eventually, and the regulators are getting faster.
Final Thoughts
Across this two-part series I’ve tried to draw a clear line between data protection (one specific principle among nine) and data privacy (the broader discipline that contains it). I’ve tried to show that personal data is far broader than the obvious identifiers, that the data lifecycle has seven phases where things can go wrong, and that the privacy principles are not abstract law but a practical framework for ethical engineering. I’ve tried to connect privacy to the threat modelling, supply chain, and post-quantum work from the previous series, because they are not separate problems: they are the same problem viewed from different angles.
There is more to say. Privacy threat modelling deserves its own deep post. The intersection of privacy and AI agents (and the inference threats that come with them) deserves another. The right to erasure in the era of vector databases and trained models is a problem we have not begun to solve. The dark patterns catalogue is going to keep growing as the industry keeps inventing new ways to game consent.
But none of that goes anywhere unless the foundation is right. Know what data you have. Know who it belongs to. Know what you’ve promised them. Make those promises in language they can read. Honour them by default, not on request. And when the values on your website don’t match the experience in your product, fix the product, not the page.
Stay tuned!
You may also like:

Threat Modeling Your Dependencies - Part 2
Mitigating Third-Party Component Risk: Swapping the Cancer for...

Threat Modeling Your Dependencies - Part 1
How One Bad Library Can Poison Your Entire...
Your SBOM Data Has Been Gathering Dust - Until Now
I’ve been talking about graphs for dependency analysis...

Data Protection and Data Privacy - Part 1 of 2
Untangling the Confusion People often confuse these two...