Get PQC Ready PDQ - Part 1


Quantum, AI, and the Window That’s Already Closing
When we talk about the threat to cryptography, the conversation almost always defaults to one word: quantum. A sufficiently large quantum computer running Shor’s algorithm breaks RSA, Diffie-Hellman, and ECC. That’s the headline, and it’s correct.
But there are actually three distinct ways to break the cryptography we depend on. The first is the mathematical attack: find a polynomial-time algorithm for the underlying hard problem. Shor’s algorithm is the example everyone reaches for. The second is the implementation attack: find a flaw in how the maths got turned into code. This is how cryptography has overwhelmingly been broken in practice, from the Debian OpenSSL RNG bug to Heartbleed to ROCA to the padding oracle attacks that took down TLS variant after TLS variant. The third is the design and protocol attack: find a flaw in how the primitives have been composed into a scheme, a protocol, or a parameter choice.
For decades, all three required deep specialist expertise and sustained effort: a researcher willing to spend months staring at the same primitive looking for an angle. That ceiling on supply has been one of the quiet reasons our existing cryptography has held up despite the steady drumbeat of CVEs.
That ceiling is now collapsing. Over the past few weeks, Claude Mythos Preview, an unreleased frontier model from Anthropic, has found a 16 year old vulnerability in FFmpeg that automated test tools had hit five million times without finding, a 27 year old bug in OpenBSD (an operating system with a reputation for being one of the most hardened in existence), and an autonomous chain of Linux kernel exploits discovered without human steering. Anthropic claims Project Glasswing has identified thousands of zero-days, including some in every major operating system and every major web browser.
Now ask the right question: if AI can find subtle defects in general-purpose code at this scale, what is it going to find in our cryptographic implementations?
Cryptographic code is exactly the kind of code that AI is well-suited to scrutinise. It is small, well-bounded, has crisp correctness criteria, and a rich history of subtle defects to learn from. The discovery cost for cryptographic flaws (both in implementations and, increasingly, in protocols and parameter choices) is collapsing in parallel with the discovery cost for general bugs.
So the threat to cryptography is no longer just “wait until a quantum computer exists.” It is the combination of three pressures, all tightening at once:
- Quantum will eventually break the asymmetric primitives outright.
- AI is rapidly compressing the cost of finding implementation flaws in the cryptography we have today.
- AI is also starting to be applied to the resource-estimation and design-side problems that determine when quantum becomes practical, accelerating that timeline as well.
This is the first of a two-part series on Post-Quantum Cryptography (PQC) readiness. In this part, I’ll cover why PQC matters, why it’s more urgent than most organisations think, what’s actually affected, and what the regulators are now saying. In Part 2, I’ll cover the plan: awareness, inventory, agility, the roadmap, and the cost. I’ll connect this back to my supply-chain trust score work, because PQC readiness is, fundamentally, another dimension of supply-chain trust.
Let’s begin.
Why this matters: a different kind of cryptanalysis
Let’s go deeper on the three pressures, starting with the one most people know.
Shor’s algorithm would break the asymmetric cryptography that the modern internet runs on. RSA, Diffie-Hellman, ECDSA, ECDH: all rely on the practical infeasibility of factoring large integers or computing discrete logarithms on classical hardware. Shor’s algorithm, executed on a sufficiently large fault-tolerant quantum computer, makes both problems tractable. That’s catastrophic for any system relying on those primitives.
Grover’s algorithm provides a quadratic speedup for unstructured search and is often described as halving the effective security of symmetric ciphers and hash functions. AES-128 effectively becomes AES-64; SHA-256 becomes SHA-128. The practical impact is widely debated (the attack requires sustained, sequential quantum operations on coherent state, which is enormously hard) and NIST’s own analysis has consistently downgraded the practical Grover threat. The mainstream cryptographic view is that AES-256 remains comfortable; AES-128 needs upgrading; SHA-2 and SHA-3 at standard sizes are fine.
So far, so familiar. These are the mathematical attacks: changes in the underlying assumption that the relevant problems are hard.
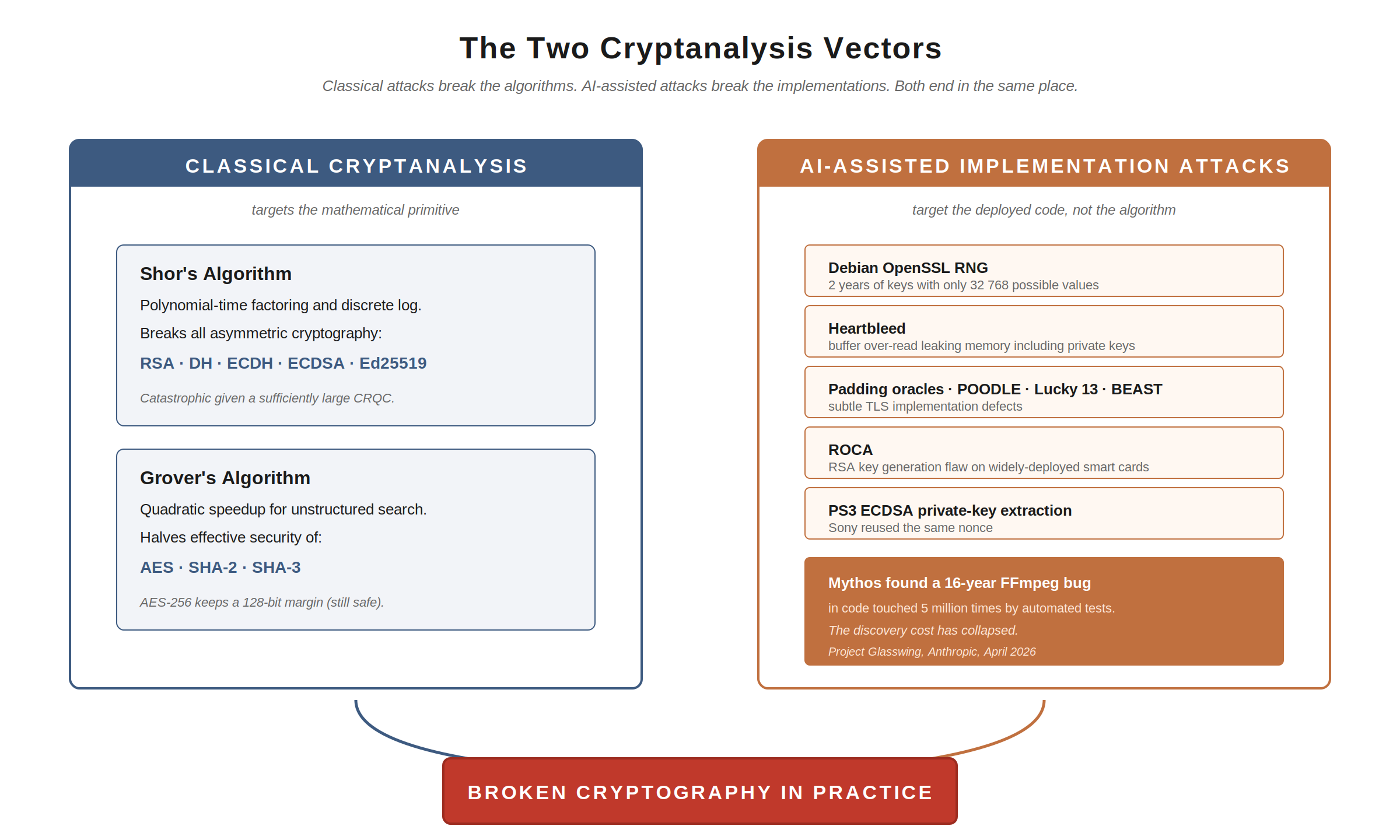
But, as I flagged in the opening, this is only one of three attack surfaces. The other two are implementation and design, and both have historically had a far better track record of actually breaking cryptography in production than the algorithm-level attacks have.
Cryptography in the wild has rarely been broken by attacks on the algorithms themselves. It has overwhelmingly been broken by attacks on the implementations:
- The Debian OpenSSL RNG bug, where keys generated for two years had only 32 768 possible values
- Heartbleed, a buffer over-read that exposed memory contents including private keys
- ROCA, a flaw in RSA key generation in widely deployed smart cards
- Padding oracle attacks against TLS, IPSec, SSH
- Lucky 13, the BEAST attack, the CRIME attack, the POODLE attack
- The PlayStation 3 ECDSA private key extracted because Sony reused the same nonce
Every one of these was a flaw in code that had passed reviews, tests, and audits. Every one of these was found, eventually, by a human or small team of researchers willing to spend weeks or months staring at the same primitive looking for an angle. The supply of those researchers has been the limiting factor.
That supply is what AI is changing. Cryptographic implementations are exactly the kind of code that AI is well suited to scrutinise: small, well-bounded, with clear correctness criteria, and a long history of subtle defects to learn from. The Mythos findings I mentioned in the opening (FFmpeg, OpenBSD, Linux kernel) are general-purpose code. Cryptography is harder for humans to audit but easier for AI to bound, because the correctness criteria are formal in a way that general code’s never are.
Note to engineering leaders: even before a cryptographically relevant quantum computer (CRQC) exists, the harvested ciphertext sitting in adversary archives may become decryptable by a classical attacker, because an AI model finds the implementation flaw that nobody noticed in twenty years. This compresses the threat window in a way the conventional Mosca discussion does not capture.
Mosca’s inequality: you are probably already late
Michele Mosca formalised the urgency calculation as an inequality (often, incorrectly, called Mosca’s theorem; it is not).
The inequality is:
X + Y > Z
Where:
- X is the security shelf-life of your data (how long it must remain confidential or trustworthy)
- Y is the time required to migrate your cryptographic infrastructure to PQC
- Z is the time until a CRQC exists
If X + Y > Z, you have already failed for that data class. Data harvested today, with shelf-life X, will still be sensitive after Y years of migration; but a CRQC will arrive within Z years, before the migration is complete.
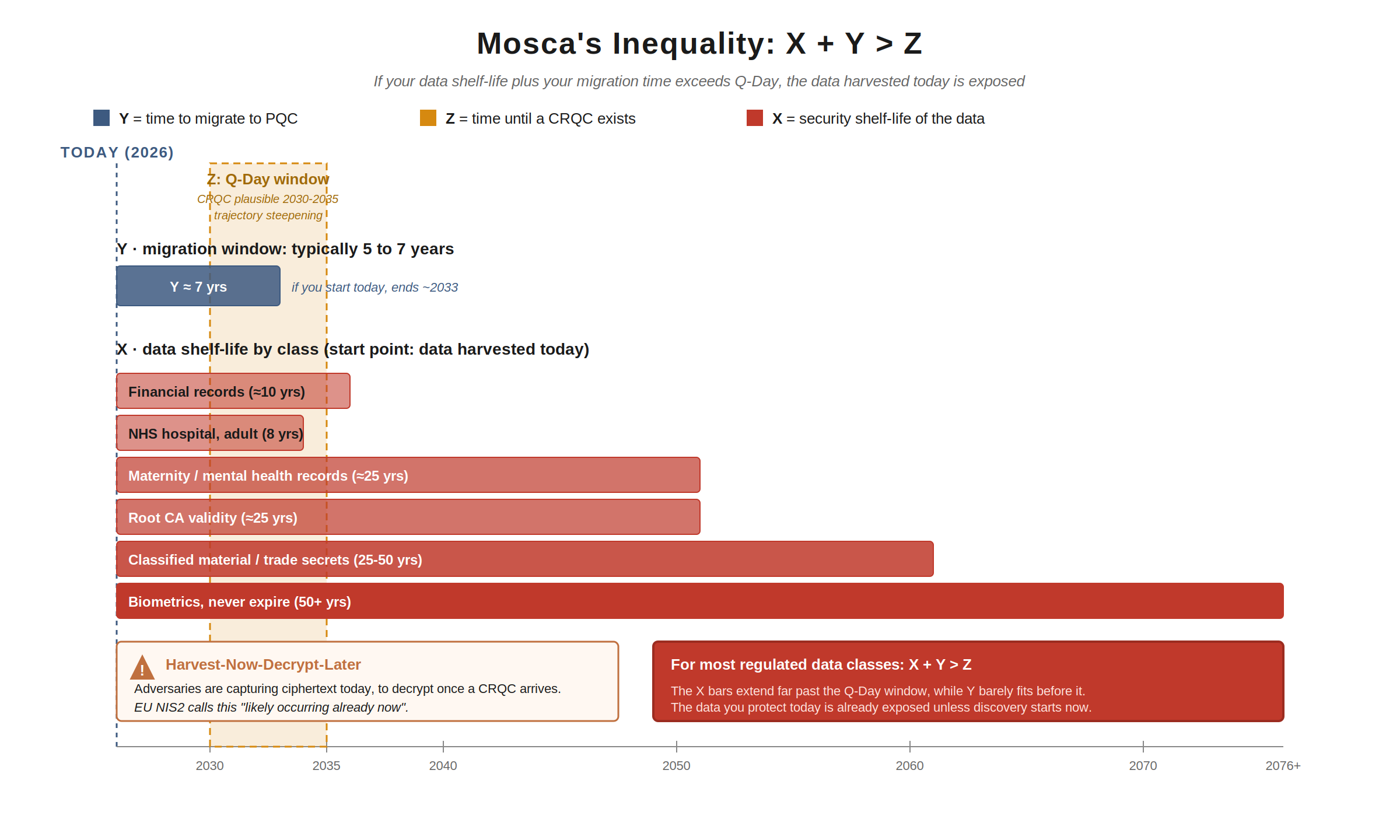
Three observations.
First, Y is not small. The UK NCSC, NSA, NIST, and EU NIS Cooperation Group all assume migration timelines measured in years. NCSC’s headline target is 2035. CNSA 2.0’s target is 2035. The EU NIS Cooperation Group roadmap targets 2030 for critical infrastructure and 2035 for everything else. NCSC’s three-phase timeline allocates 2025-2028 just to discovery. If you started your discovery exercise tomorrow, full migration by 2035 is a credible plan; if you start in 2028, it is not.
Second, Z is contracting fast. Three resource-estimate papers in the last ten months have collapsed the quantum threat budget by orders of magnitude:
- Gidney, May 2025 (arXiv:2505.15917) revised the cost of factoring RSA-2048 from his own 2019 figure of 20 million noisy qubits down to fewer than one million, completing the factorisation in under a week. 20x reduction in six years.
- Iceberg Quantum’s Pinnacle architecture, February 2026 proposed using quantum LDPC codes in place of surface codes, suggesting RSA-2048 may be tractable with fewer than 100,000 physical qubits at standard error rates. Another order of magnitude below Gidney. The result is simulation-based and not yet experimentally validated, so treat it as a directional signal rather than a settled estimate.
- Google Quantum AI, Stanford, and the Ethereum Foundation, 31 March 2026 (arXiv:2603.28846) showed that the 256-bit elliptic curve discrete logarithm problem (ECDLP-256) on secp256k1 (the curve used by Bitcoin, Ethereum, and many other systems) is breakable with fewer than 500,000 physical qubits in a runtime measured in minutes, a 20x reduction over the previous best estimate from 2023.
These are all resource estimates, not demonstrations. The hardware does not yet exist at these scales, and the Iceberg numbers in particular still need experimental validation. But every published resource-estimate paper since 2019 has revised the budget downward, and the trajectory is the only thing that matters for Z. The hardware lag is what is keeping us safe; the hardware lag is also what is closing.
The March 2026 result is the one most under-discussed in PQC awareness conversations, and it matters disproportionately. A common assumption among engineers is that moving from RSA to ECC has bought time for the migration. It hasn’t. ECDLP-256 is now in the same compressed threat space as RSA-2048, with a tighter resource budget and a faster runtime. Anything you have built on ECDH, ECDSA, P-256, secp256k1, or Ed25519 is exposed on the same horizon as RSA, not later.
Third, X is set by law and contract, not by you. We’ll come to this next.
Why we MUST move: data shelf-life, regulation, and contract
The shelf-life of data is not negotiable. It is determined by what the data is, who you have a duty of care to, what regulators require, and what contracts you have signed.
Consider:
- Personal data under GDPR: must be retained no longer than necessary for the purpose (Article 5(1)(e)), but for many lawful purposes (employment records, financial transactions, medical care) “necessary” runs to decades. A breach of data harvested today and decrypted in fifteen years is still a breach of GDPR-protected personal data.
- Health records: in the UK, NHS hospital records for adults are retained for at least 8 years after last treatment, GP records are retained for the patient’s lifetime plus 10 years after death, and maternity and mental health records for 20 to 25 years. HIPAA in the US requires 6 years minimum, but state law commonly extends this; for paediatric records the practical horizon is multi-decade in both jurisdictions.
- Financial records: typically 5 to 7 years for tax purposes, 10+ years for mortgage and lending, with much longer retention for fraud and AML investigations. Pension records routinely require multi-decade retention.
- Identifying biometrics: a fingerprint or iris scan harvested today identifies the same human in 2070. Biometrics are forever.
- Intellectual property and trade secrets: shelf-life is “until the IP loses commercial value,” which for fundamental research, pharmaceutical pipelines, or proprietary manufacturing processes can be the lifetime of the company.
- Classified material: typically 25 years to indefinite, depending on classification and jurisdiction.
- Long-validity signatures: the signed mortgage contract you executed today is a legal instrument for the term of the mortgage. Code signing certificates routinely have 3 to 5 year validity, but the signed code is verified for as long as it runs. A root CA can have a 20 to 25 year lifetime.
When I implemented digital signature support for non-repudiable banking contracts, the validity window was the full term of the contract, plus the limitation period for any dispute. The cryptography protecting that signature must remain unbroken for that entire window. If that window crosses Q-Day, the contract’s evidential weight collapses.
Note to compliance leaders: any data class with shelf-life beyond 2030 (and certainly beyond 2035) is, in Mosca terms, already exposed. The harvest-now-decrypt-later (HNDL) threat is not theoretical. The European Commission’s recent proposal to amend NIS2 explicitly recognises HNDL as “likely occurring already now”. Your retention obligations are a direct enumeration of your PQC priorities.
What is affected, and why
Cryptography in modern systems falls into three overlapping uses, and each has a different exposure profile under quantum and AI-assisted attack. The framing here matters because the conventional wisdom on at-rest encryption is, in my view, often communicated badly.
Encryption in transit
This is the clearest case. TLS, IPSec/IKEv2, SSH, WireGuard, QUIC, and similar protocols all rely on asymmetric primitives (RSA, ECDH, ECDSA) for key exchange and authentication. Once Shor is on the table, those primitives are broken, and any session captured before the migration completes is decryptable retroactively if the asymmetric handshake was used to establish the session keys.
This is the canonical HNDL surface. Sensitive data with multi-year shelf-life that traverses the public internet today is already at risk, because the ciphertext can be (and likely is being) harvested.
The good news is that this is also the most ecosystem-supported migration path. Hybrid TLS 1.3 key exchange combining classical (X25519) with PQC (ML-KEM) is already deployed in production by Cloudflare, Google, AWS, Apple iMessage, and others. NCSC, NSA, and NIST all explicitly allow hybrid as the responsible default during transition; the EU PQC roadmap actively recommends it.
When I implemented TLS support for a BPMN platform used in banking, the cipher suite negotiation, certificate management, and HSM integration were complex enough on their own. PQC adds new dimensions: ML-KEM ciphertexts are kilobytes rather than tens of bytes, which changes assumptions in some protocols and stresses MTUs in others. Plan for the protocol-level work as well as the algorithm change.
Signing and hashing
This is the use case that, in my view, is most under-prioritised in PQC discussions, and where I’d push back against the common “transit first, signing later” framing.
A signature is a long-tail commitment. The TLS session you set up today might last seconds or hours; the signature you put on a contract, a piece of code, or a firmware image lasts as long as that artefact has legal weight or is in operational use. Specifically:
- Code signing: a kernel module, OS update, or container image signed today is verified by every system that consumes it, indefinitely. Adversaries who can forge signatures can ship malicious updates that look authentic.
- Firmware signing: devices shipped today with PQC-incapable firmware verification often have 10 to 25 year operational lifetimes (industrial control systems, medical devices, vehicles, satellites). They cannot be easily updated.
- Document signing: eIDAS qualified electronic signatures, digital notarisations, and similar legal instruments are designed to be evidential for decades.
- Root certificate authorities: typically have 20 to 25 year validity. A root CA signed today underwrites trust until the late 2040s.
Two things follow. First, signing migration deserves a parallel track to transit migration, not a sequential one. The HNDL threat for transit and the long-validity threat for signatures both demand action now, but they affect different parts of the stack and can be progressed concurrently.
Second, we already have stateful hash-based signature schemes (LMS and XMSS, standardised by NIST in SP 800-208) that are quantum-resistant and ready for use today for code and firmware signing. They have operational caveats (state must be carefully managed; key reuse is catastrophic) but they exist, are NSA-recommended for software and firmware signing under CNSA 2.0, and have implementations ready. There is no reason to be waiting for ML-DSA to deploy quantum-resistant signing on long-lived artefacts; you can start now with hash-based signatures.
Hashing itself is the easiest case. SHA-256 and SHA-3 at standard widths remain comfortably secure under Grover; the recommendation is simply to prefer SHA-384 or SHA-512 where the option exists, and CNSA 2.0 makes this explicit.
Encryption at rest
This is where the conventional framing tends to fail, and where I want to be careful.
You will hear “AES-256 is fine, you don’t need to worry about data at rest.” That is half-true and dangerous when stated alone.
AES-256 itself is fine. Grover halves its effective security to a 128-bit margin, which remains comfortable. Grover-on-AES is also widely doubted as a practical attack for the reasons mentioned earlier. NIST’s transition timelines recommend AES-256 for any new symmetric encryption with long shelf-life data; that is the right call.
The problem is that the AES key protecting your data at rest is almost never standalone. In any non-trivial deployment, that key sits inside a key hierarchy:
- A data encryption key (DEK) encrypts the data
- The DEK is wrapped by a key encryption key (KEK)
- The KEK is itself often protected, transferred, or attested using asymmetric cryptography (RSA-OAEP, RSA-KEM, ECDH key agreement, RSA signatures for attestation, certificates for KMS authentication)
- The KMS or HSM authenticates clients, often via TLS using RSA or ECDSA, and signs audit logs using the same primitives
Break the asymmetric layer and you don’t need to break AES; you walk in through the front door.
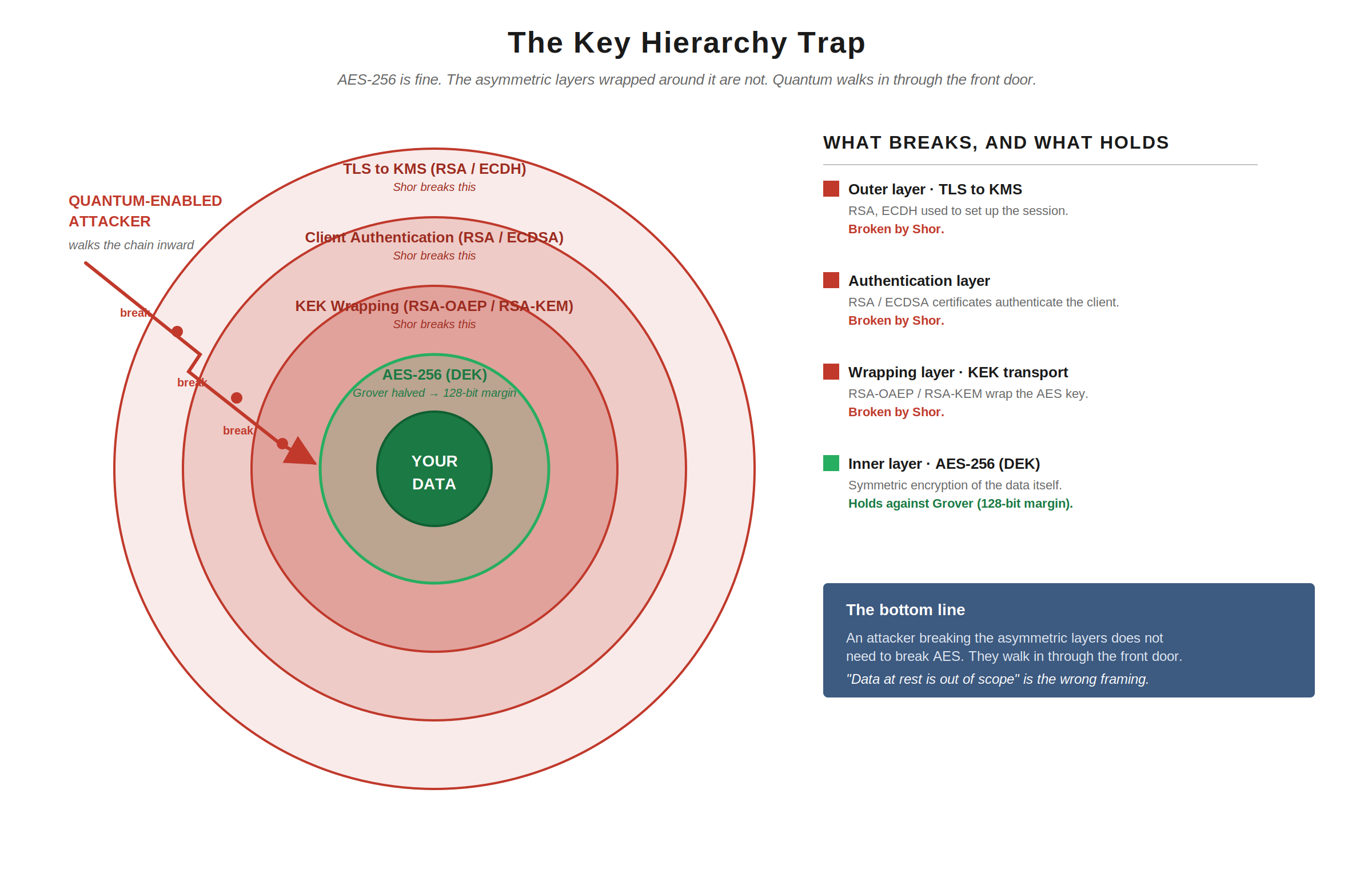
When I implemented encryption at rest for systems handling regulated data, the AES layer was the easy part. The hard parts were key wrapping, KMS authentication, attestation, and audit. Every one of those today depends on asymmetric primitives that Shor breaks.
This is why “data at rest is out of scope” is the wrong framing. What’s true is that the symmetric primitive needs only a key-size uplift. What’s also true is that the system that delivers, manages, and authenticates the use of that primitive is mostly asymmetric, and is fully in scope. NIST’s PQC programme has historically focused on the asymmetric replacements because that’s where the cryptographic standardisation effort sits, but that does not mean at-rest systems get a free pass. They don’t.
Supply chain: PQC readiness as a new trust dimension
In my previous series on supply-chain risk, I introduced the Supply-Chain Trust Score: a way to quantify and propagate the risk of third-party components through your dependency graph. PQC readiness is, structurally, another dimension of that trust score.
Your TLS stack’s PQC readiness is bounded by your TLS library’s readiness, which is bounded by your cryptographic provider’s readiness, which is bounded by your HSM vendor’s readiness. The propagation works exactly the same way the existing trust score propagates. Effective PQC readiness is the minimum across the chain, and a single laggard at depth 3 in your dependency graph can hold up the migration of every application above it.
This will be a substantial section of Part 2. For now, the key point is: your PQC migration is not a project you control end-to-end. It is a coordination problem across your suppliers, and the trust-score lens is the right way to think about it.
The regulatory landscape
Even if Mosca and the technology threat were not enough, the regulators have made the timeline explicit. The headlines:
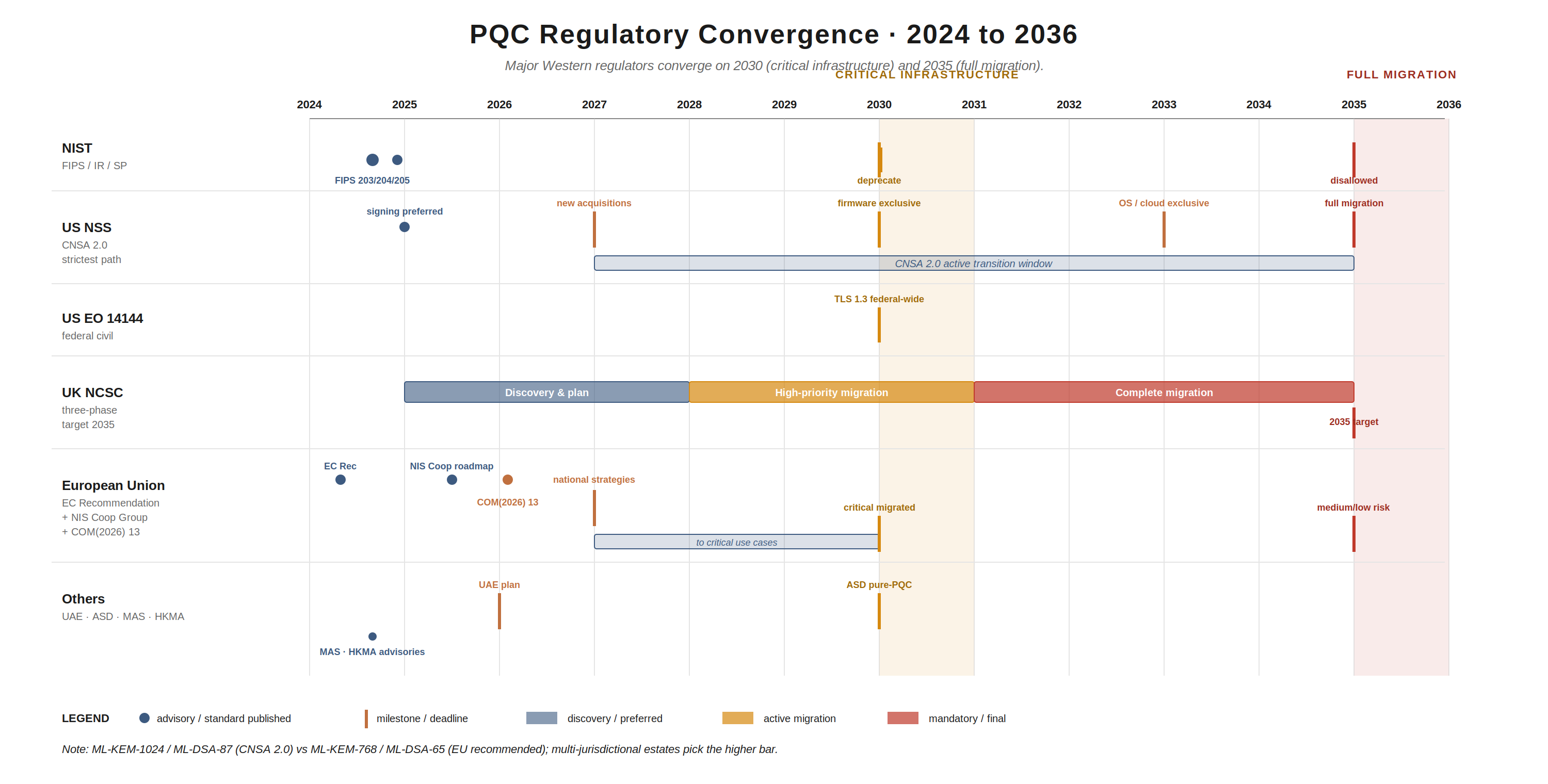
United States:
- NIST FIPS 203 (ML-KEM), FIPS 204 (ML-DSA), FIPS 205 (SLH-DSA) finalised August 2024; FN-DSA (FIPS 206) draft. SP 800-208 (LMS/XMSS) since 2020. SP 1800-38 (cryptographic agility migration practice guide). NIST IR 8547 (Nov 2024) sets RSA-2048 / ECC P-256 deprecation by 2030 and disallowed by 2035.
- NSM-10 (May 2022) directs federal agencies to migrate. OMB M-23-02 (Nov 2022) requires federal agencies to inventory cryptographic systems. Quantum Computing Cybersecurity Preparedness Act (Dec 2022) codifies inventory and migration planning obligations.
- CNSA 2.0 (NSA, updated Dec 2024) sets the most aggressive timeline in any Western framework: code/firmware signing preferred 2025, mandatory new acquisitions Jan 2027, firmware signing exclusive 2030, OS/cloud/applications exclusive 2033, full migration 2035. CNSA 2.0 mandates the highest-strength PQC parameters: ML-KEM-1024, ML-DSA-87, AES-256, SHA-384/SHA-512.
- Executive Order 14144 requires TLS 1.3 (or successor) across all federal systems by 2 January 2030.
United Kingdom:
- NCSC published Timelines for migration to post-quantum cryptography in March 2025. Three phases: to 2028 (discovery and migration plan); 2028 to 2031 (high-priority migration); 2031 to 2035 (complete migration).
- Aimed primarily at large organisations, critical national infrastructure, and bespoke IT estates. NCSC notes that for many small and medium organisations, migration will arrive transparently via vendor upgrade cycles.
European Union:
- Commission Recommendation (April 2024) called on Member States to develop a Coordinated Implementation Roadmap.
- NIS Cooperation Group Roadmap Part 1 published June 2025. Member States to publish national PQC strategies and start cryptographic inventories by end of 2026; critical use cases migrated by 2030; medium and low risk by 2035.
- COM(2026) 13 (Jan 2026) proposes amendments to NIS2 making PQC migration planning a named, mandatory component of national cybersecurity strategy, and explicitly recognises HNDL as a present threat.
- Recommended parameters: ML-KEM-768, ML-DSA-65 (less stringent than CNSA 2.0; multi-jurisdictional organisations will need to pick the higher bar where they overlap).
- CRA (Cyber Resilience Act) and DORA (Digital Operational Resilience Act) both impose duties that, while not naming PQC explicitly, require state-of-the-art cryptography, and the EU has now made it clear that quantum-vulnerable cryptography does not meet that bar.
Other jurisdictions:
- UAE: organisations operating in scope must submit a PQC migration plan in 2026.
- Australia (ASD): pure-PQC requirement by 2030 for regulated sectors.
- Singapore (MAS) and Hong Kong (HKMA): PQC readiness advisories already issued for the financial sector, signalling supervisory expectations.
- Bank of England and CEPS Task Force: have warned of systemic risk to financial systems and urged immediate cryptographic asset inventories.
Two things stand out from this landscape.
First, the regulators have converged on 2030 and 2035. 2030 for critical infrastructure and high-priority systems; 2035 for full migration. If you run a multi-jurisdictional estate, the most stringent applicable jurisdiction governs, and increasingly that’s CNSA 2.0 (which pulls in defence supply chain and SaaS vendors via procurement).
Second, inventory comes first, everywhere. Every regulator, without exception, asks for cryptographic and data inventories as the first deliverable. If you do nothing else this year, do the inventory. We’ll cover how in Part 2.
Final Thoughts
Three things, then I’ll wrap up.
Quantum is no longer a far-future threat in regulatory eyes. The window NCSC, NSA, NIST, the EU, and ENISA have left for migration runs to 2035, and they have allocated the first three to four years to discovery. If you start in 2028, you don’t make 2035.
AI-assisted cryptanalysis tightens the window further. Even before a CRQC exists, the harvested ciphertext sitting in adversary archives may become decryptable because an AI model finds the implementation flaw nobody noticed. Mythos finding a 16 year old vulnerability in code touched by five million automated tests is the writing on the wall. Your defence in depth needs to assume that algorithmic strength is not enough, and that implementation review at scale (likely AI-assisted itself) is part of the migration plan.
The regulators are right that inventory comes first. You cannot migrate what you cannot see. Most organisations cannot enumerate the cryptographic primitives in use across their estate today, let alone the long-shelf-life data that depends on them. That gap is the single biggest blocker to acting on Mosca, and it is what Part 2 will tackle in detail.
Note to engineering leaders: if your most senior architect cannot, in the next 30 minutes, tell you which of your applications use RSA, where your KEKs are wrapped, and what the validity window is on your code-signing certificates, you have an inventory problem before you have a PQC problem. The good news is that your inventory work is also required by CNSA 2.0, OMB M-23-02, NCSC’s first phase, the EU NIS Cooperation Group roadmap, and the proposed NIS2 amendments. One piece of work satisfies multiple regulators, and gives you the foundation for everything that follows.
In Part 2, I’ll get into how you do that inventory (and why a CBOM is not what most people think it is), how to plan the migration strategically, what the cost actually looks like for small, medium, and large organisations, where AI helps and where it doesn’t yet, and the roadmap order I’d recommend.
Stay tuned!
You may also like:

Get PQC Ready PDQ - Part 2
The Plan, the Order, and the Bill In...

Threat Modeling Your Dependencies - Part 2
Mitigating Third-Party Component Risk: Swapping the Cancer for...

Threat Modeling Your Dependencies - Part 1
How One Bad Library Can Poison Your Entire...

Data Protection and Data Privacy - Part 1 of 2
Untangling the Confusion People often confuse these two...