Get PQC Ready PDQ - Part 2


The Plan, the Order, and the Bill
In Part 1 I argued that the quantum threat is closer than most engineering organisations are acting on, that AI-assisted cryptanalysis tightens the window further, that Mosca’s inequality already says you should have started, and that every major Western regulator has converged on 2030 and 2035 as the dates that matter.
If that’s where we are, the question that follows is: now what do we actually do about it?
In this part, I’ll cover the plan: awareness, cryptographic agility, the inventory work nobody enjoys but everybody needs, the strategic and economic argument for moving early, a bottom-up view of what migration actually costs, the order I’d recommend, and the role AI plays in the migration itself (the same capability that makes the threat is also the most useful tool for defending against it).
Let’s begin.
Awareness and education: get this wrong, and the rest doesn’t matter
The first step, is making sure the engineering and product organisations understand what’s being asked of them.
A typical engineer has interacted with cryptography in three ways: configuring TLS cipher suites, calling a crypto.encrypt() function in some library, and arguing about whether to use SHA-256 or SHA-512. The mathematics behind the algorithms, the protocol-level interactions, the difference between a primitive and a scheme, the role of the KMS and HSM in their architecture: all of this tends to be a vague memory from a university module nobody enjoyed.
That is not a criticism. It’s a description of the field as it actually exists. Cryptography is a deep specialism, and most engineers have, until now, been able to delegate the hard parts to libraries and standards bodies.
PQC migration isn’t that simple anymore. The standards are not mature enough yet and won’t be for years, which means the choices that used to be made for you are now choices the teams has to make. Should you use ML-KEM-768 or ML-KEM-1024? It depends on which regulators you answer to. Should your hybrid TLS run X25519+ML-KEM or P-256+ML-KEM? It depends on what your clients support. Should you migrate signing first or TLS first? It depends on the shelf-life of what you’re protecting. These are not questions a library can answer for you.
So before kicking off any inventory or migration work, invest in:
- A short, deliberate education programme for engineering, product, and security teams.
- Regular architecture workshops that walk through the algorithm changes, the size and performance implications (ML-DSA signatures are roughly 2.4 KB versus 64 bytes for Ed25519; ML-KEM ciphertexts are kilobytes), and the protocol-level changes that follow.
- Plain-English material for product managers and senior leadership so that when migration shows up in the backlog, they understand what they are sponsoring.
Note to engineering leaders: the quality of your migration plan is bounded by the cryptographic literacy of the people writing and reviewing it. Skip this step and you’ll re-litigate the same architectural questions every sprint.
Cryptographic agility: the principle that should already be in your codebase
Cryptographic agility is the ability to change cryptographic primitives, parameters, or schemes without code changes. It is the single most important enabling principle for PQC migration, and most codebases do not have it.
A codebase with poor agility looks like this:
- Algorithm names hardcoded inline (
Cipher.getInstance("RSA/ECB/OAEPWithSHA-256AndMGF1Padding")) - Key sizes baked into types and serialisation formats
- Certificate validation logic with explicit primitive checks
- Protocol implementations that assume specific output sizes
A codebase with good agility looks like this:
- Algorithm choices in configuration, not in code
- Abstracted key handling (
KeyFactory.getKey(name)) where the calling code doesn’t know whether it’s getting RSA, ECC, or ML-KEM - Encryption services (cloud KMS, internal services) called via a stable interface
- Output sizes treated as variable, with packets / fields / databases sized for the largest expected primitive
NIST has a dedicated special publication for this SP 1800-38, and it’s worth reading. The principles are not new (good engineers have been writing for crypto-agility for years), but the urgency is.
For small organisations, the practical implication is: don’t roll your own, use an encryption service. AWS KMS, Azure Key Vault, Google Cloud KMS, HashiCorp Vault, and similar services are all working through PQC migration internally. If you’re consuming them via stable APIs, you inherit most of the migration work. If you’re calling primitives directly from your application code with hardcoded algorithm names, you are about to do that migration work yourself.
For larger organisations with bespoke infrastructure, you need to do the agility work first, before the migration. Migrating an inflexible codebase is much more expensive than migrating an agile one. The good news is that the agility work is independently valuable: it makes future cryptographic changes (algorithm deprecations, key rotation, parameter changes) into configuration changes rather than code releases.
The inventory work nobody enjoys, but everybody needs
Every major regulator agrees on this: the first deliverable of a PQC migration programme is an inventory. NIST IR 8547, OMB M-23-02, NCSC’s Phase 1 (to 2028), the EU NIS Cooperation Group roadmap (cryptographic inventories by end of 2026), and the proposed NIS2 amendments all require this work.
But the inventory is not one thing. It is two things, both required, and they are usually conflated in a way that hides important gaps.
Two inventories, two purposes
A data inventory tells you what data you hold, where it sits, who is responsible for it, and how long it must remain confidential or trustworthy. It must cover the full lifecycle: collection, creation, consent, processing, storage, inference, rotation, transfer, destruction. Each lifecycle stage has different cryptographic exposure.
For PII, the inventory needs to cover the effective value of the data over time: a piece of data may be sensitive on day one and effectively worthless on day 3 650, or it may be sensitive forever (biometrics, medical history). Without a view of effective value over time, you cannot prioritise which data classes need quantum-resistant protection first.
A cryptographic inventory tells you what primitives, parameters, keys, certificates, and protocols are actually in use across your estate. It needs the lifecycle of the cryptographic primitives themselves: when a key was generated, by whom, how it is rotated, when it expires, where it is wrapped, where it is stored, where it is used, what it is used for, and how it is destroyed.
These are two different inventories with two different sets of stakeholders. Trying to combine them tends to produce a spreadsheet that does neither job well.
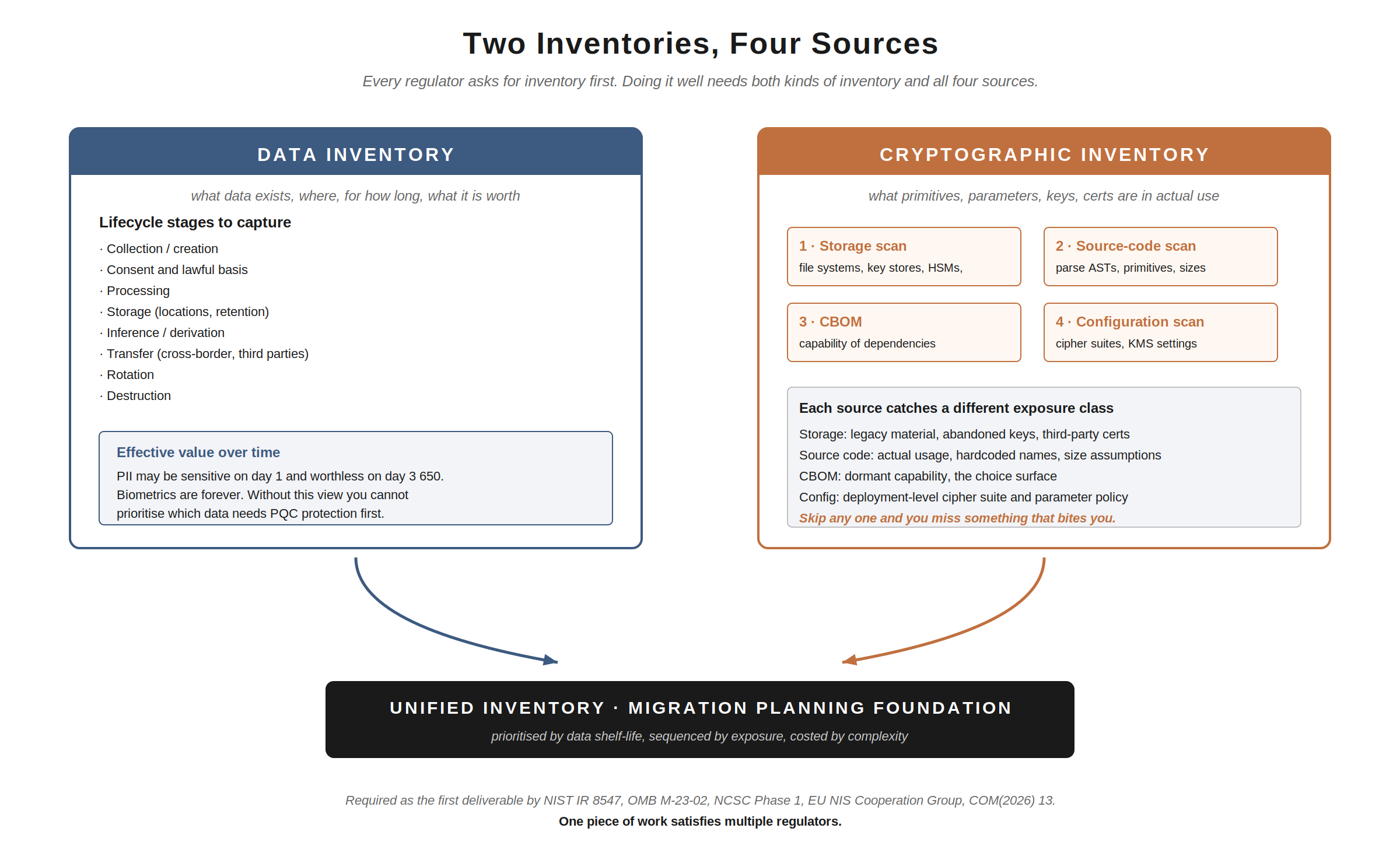
The cryptographic inventory has two sources
This is where most organisations cut corners and pay for it later.
Source one: storage. Scan your file systems, key stores, certificate stores, HSMs, and TLS endpoints. This catches the third-party and legacy material: certificates whose origin nobody remembers, keys in HSMs whose use case has moved on, archived encrypted files, signing keys for code that’s still in production. Most large organisations are already doing some version of this through certificate lifecycle management (CLM) tooling.
Source two: source code. Parse the source code of your applications and extract metadata about what they actually use: which libraries they import, which algorithms they call, which key sizes they specify, which protocols they negotiate. This catches the application-level picture that storage scans cannot: how cryptography is used in the code, where assumptions about primitive sizes are baked in, where algorithm names are hardcoded, where protocol versions are pinned.
When I was building the source code search engine for BlackDuck (Koders.com), and later when I built lexers and parsers for the script language interpreter on the BPMN platform, the work involved exactly this kind of metadata extraction at scale: walking ASTs, resolving symbol references across files, indexing the result so it can be queried meaningfully. The same techniques applied to your application codebase will produce the cryptographic inventory you need.
These are two different scans, producing two different views, and you need both. Storage tells you what exists; source code tells you what is used. The intersection (and, crucially, the gaps) tells you what to migrate, in what order, and with what confidence.
What a CBOM is, and what it is not
The Cryptographic Bill of Materials (CBOM, an extension of CycloneDX SBOM) gets discussed as if it solves the cryptographic inventory problem. It does not, and the distinction matters.
A CBOM tells you what cryptographic primitives the libraries in your dependency tree implement. So if your application depends on Bouncy Castle, the CBOM will list every cryptographic primitive Bouncy Castle supports: RSA, ECDSA, AES, SHA family, plus a long list of things you have probably never used.
A CBOM does not tell you what your application actually calls. If your application uses precisely two primitives from Bouncy Castle (RSA-2048 for signing and AES-256 for encryption), the CBOM will still list everything Bouncy Castle supports, including ones your code never invokes.

These are two distinct things, and combining them produces inventories that look comprehensive but mislead the migration planning. The library can do many things; your application does specific things. Migration cost depends on what your application actually does.
So a complete cryptographic inventory needs:
- CBOM: list of cryptographic capabilities present in dependencies (catches: dormant capability, algorithm choice surface)
- Source code scan: list of cryptographic primitives actually invoked (catches: real usage)
- Storage scan: list of cryptographic artefacts in production (catches: certificates, keys, encrypted blobs)
- Configuration scan: list of cryptographic parameters in deployment configuration (catches: TLS cipher suite policies, KMS configurations)
All four feed a unified cryptographic inventory. You need all four because each catches a different class of exposure. Skip any of them and you will miss something that bites you in the migration.
Note to engineering leaders: if your cryptographic inventory comes from a single tool or a single scan type, it is incomplete. Budget accordingly.
Risk and strategic planning: the case for moving early
The economics of PQC migration are straightforward in principle and uncomfortable in practice. There are two ways to do it.
Planned migration
You decide migration is a priority, allocate budget over multi-year phases, do the inventory work, build the agility, schedule the algorithm changes alongside other work, test thoroughly, validate, decommission the legacy. The work is substantial but the timeline is yours.
Emergency migration
A vulnerability is disclosed, a CVE drops on a primitive you depend on, a regulator publishes a hard deadline you missed, a customer audit flags non-compliance, or a public Q-Day announcement turns the threat from theoretical to immediate. You now do all the same work, but on a timeline measured in weeks, with a security incident as the forcing function.
The economic ratio between these is not subtle. Emergency migration is, based on industry data, three to five times the cost of planned migration for the same scope of work, before counting the cost of the incident itself, the breach risk during the rushed window, the reputational damage, and the regulatory scrutiny that follows.
The cost of being early (within the planned window) bends the other way:
- Compliance head start: when CNSA 2.0, NCSC 2031, or EU 2030 milestones bite, you’ve passed them already.
- Procurement positioning: government and regulated-industry contracts are starting to require PQC readiness statements. Organisations that can produce one have a procurement advantage.
- Reputation: in a market that’s about to be overwhelmed by breaches, the organisations that are demonstrably ahead become preferred suppliers.
- Reduced risk window: every additional year you sit on quantum-vulnerable cryptography is another year of HNDL exposure for the data you handle.
The cost of being late compounds. You miss the procurement window. You’re paying premium rates for a small pool of available cryptography talent at the precise moment everyone else is hiring them. Your auditors are no longer accepting “we’re working on it” as an answer.
Y2Q risks worth flagging
Two non-obvious risks are worth calling out:
Developer attrition. The window between now and 2035 is long enough that the engineers who built your existing cryptographic infrastructure may have moved on by the time you migrate. Tribal knowledge that lived in their heads (why is this key wrapped this way? why do we have these specific certificate profiles?) becomes lost. The inventory work mitigates this, but only if you start it while the people who can answer the questions are still around.
Experts in cryptography are rare and getting rarer. There are far more applications needing PQC migration than there are cryptographers available to advise on it. Plan for this, the cryptography consultancies will be booked solid by 2028 so make sure you have an agreement in place now while you still can, and develop in-house capability while it is still possible to recruit.
The counter-balance: AI-assisted code analysis is genuinely useful for parts of the migration. We’ll come to that, but it is not a complete replacement for experts in cryptography. It accelerates the routine parts so the experts can focus on the hard parts.
Archive data: delete it, air-gap it, or re-encrypt it
Re-encryption of stored data is a major cost item I’ll quantify in the next section. But before you spend that money, ask whether the data needs to exist at all.
Three options for archive data, in order of cost-effectiveness where they apply:
- Delete it. Under GDPR, retention beyond the original lawful purpose is itself a compliance risk. Many organisations are sitting on archives whose retention rationale dissolved years ago. Deletion is the cheapest possible PQC migration: zero re-encryption, zero ongoing exposure.
- Air-gap it. Archive data with genuine retention obligation but no operational use can be moved to physically isolated storage. Caveats: this does not undo HNDL of data harvested while the storage was online, and air-gapped systems have been compromised before (Stuxnet, supply-chain firmware attacks). Reduces attack surface dramatically; does not eliminate it. It can also potentially be kept offline and brought back online only when needed.
- Re-encrypt it. Only when neither deletion nor air-gapping is viable, and the data has shelf-life past 2030.
Run your archive estate through these three options before assuming everything needs to be re-encrypted. The cost reduction can be very substantial.
The cost: a bottom-up view
I’m going to estimate this from the ground up, piece by piece, in man-days of effort, rather than quoting you headline figures from industry reports. The reason is that headline figures vary wildly between sources (and between organisations) is because they make different assumptions about what’s already done, what’s in scope, and what counts as “migration.” Building the estimate from the work itself forces every assumption to be explicit. Your numbers will differ from mine; the point is that you can see exactly where and why.
This is a model, not a quote. Your numbers will vary based on your existing crypto-agility, your dependency on commodity vs bespoke infrastructure, your regulatory regime, and the quality of your existing cryptographic inventory.
Organisation-size definitions used here
- Small: under 100 employees, fewer than 50 applications, mostly commodity infrastructure (cloud-native, managed services), single primary regulatory regime, no in-house HSM or PKI.
- Medium: 100 to 2 000 employees, 50 to 500 applications, mix of commodity and bespoke, two to three regulatory regimes, may operate own HSMs and CAs, has dedicated security team but limited cryptographic specialism.
- Large: 2 000+ employees, 500+ applications, significant bespoke infrastructure, multi-jurisdictional regulatory exposure, operates own HSMs and PKI, has internal cryptographic specialism but stretched.
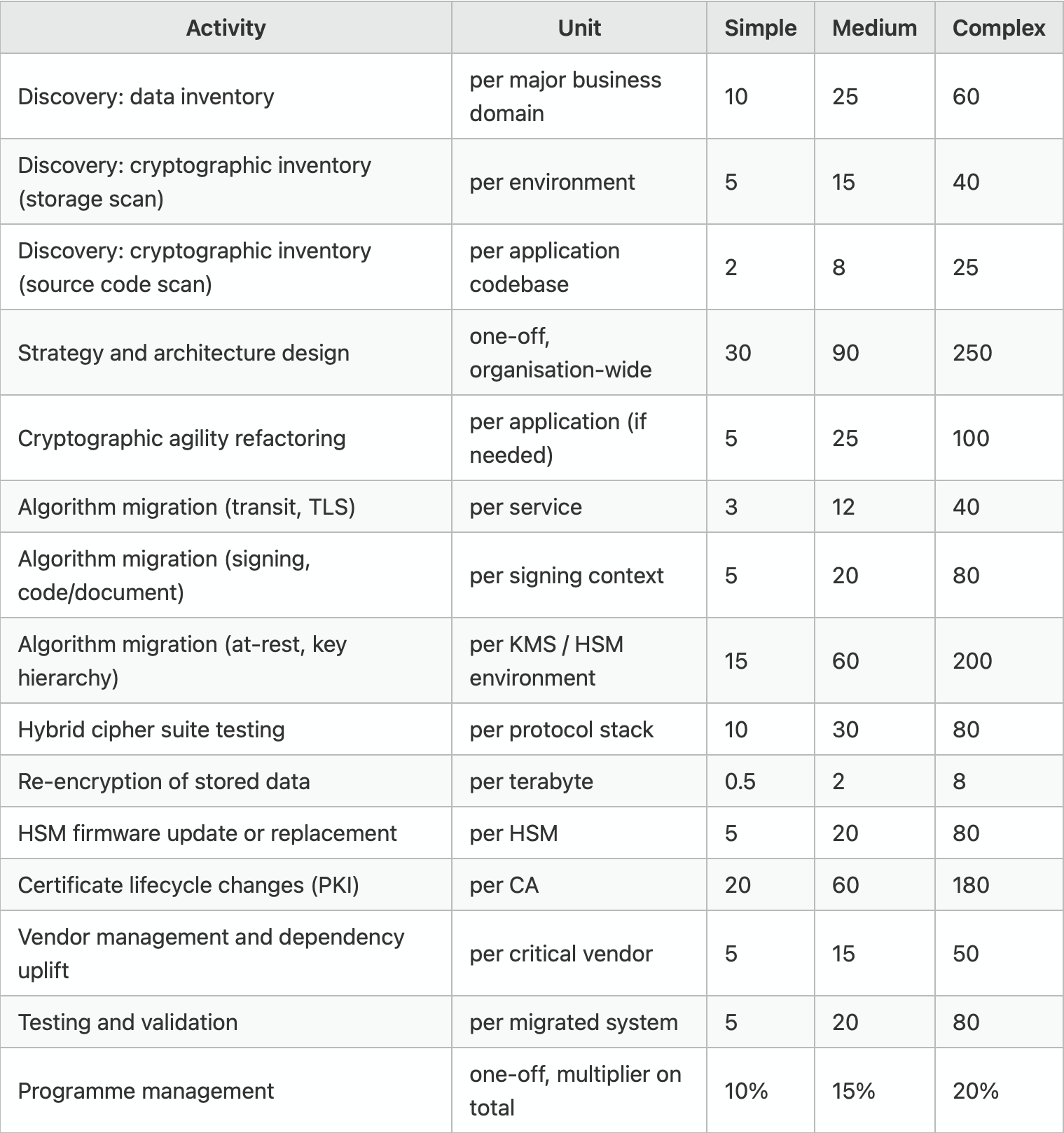
Man-days by activity (per unit, with complexity tiers)
Assumptions baked in:
- “Simple” assumes mostly commodity infrastructure, good existing crypto-agility, single regulatory regime, healthy SBOM/CBOM coverage.
- “Medium” assumes mix of commodity and bespoke, partial agility, multi-regulatory exposure.
- “Complex” assumes significant bespoke infrastructure, poor agility, multiple ecosystems, multi-jurisdictional, possibly hardware roots of trust requiring physical replacement.
- All man-days assume a fully-loaded senior security engineer or architect (UK reference rate: £700-£900 per day).
Illustrative totals by org size
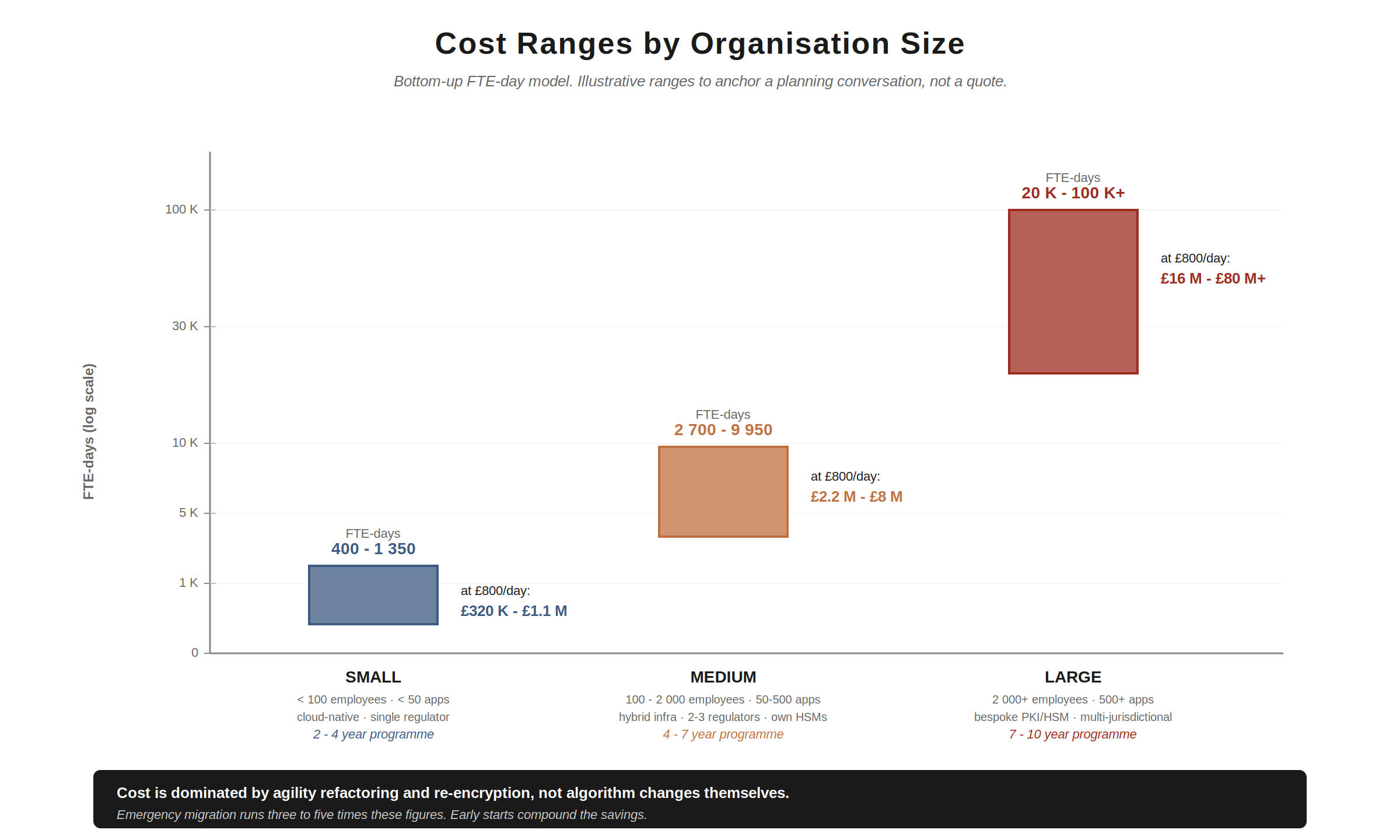
For a small organisation (50 applications, mostly cloud-native, single regulatory regime, AWS KMS or equivalent):
- Discovery (data + crypto): 50 to 150 days
- Strategy and architecture: 30 to 60 days
- Cryptographic agility refactoring (mostly already there): 50 to 200 days
- Algorithm migration (mostly inherited from cloud providers): 100 to 300 days
- Re-encryption (assume 100 TB data, of which 30 TB needs migration): 30 to 240 days
- Testing and validation: 100 to 300 days
- Programme management (10-15%): add 50-100 days
Total: 400 to 1 350 man-days. At £800 per day, roughly £320K to £1.1M.
For a medium organisation (200 applications, hybrid infrastructure, two-to-three regulatory regimes, own HSMs):
- Discovery (data + crypto): 200 to 600 days
- Strategy and architecture: 90 to 200 days
- Cryptographic agility refactoring (significant work): 500 to 2 000 days
- Algorithm migration (transit + signing + auth + at-rest): 800 to 2 500 days
- HSM and PKI work: 100 to 400 days
- Re-encryption (assume 5 PB, of which 2 PB needs migration): 200 to 1 600 days
- Vendor management: 50 to 150 days
- Testing and validation: 400 to 1 200 days
- Programme management (15%): add 350 to 1 300 days
Total: 2 700 to 9 950 man-days. At £800 per day, roughly £2.2M to £8M, spread over four to seven years.
For a large organisation (1 000+ applications, multi-jurisdictional, bespoke PKI, own HSM estate):
- Discovery (data + crypto): 1 000 to 3 000 days
- Strategy and architecture: 250 to 500 days
- Cryptographic agility refactoring (large bespoke estate): 3 000 to 15 000 days
- Algorithm migration: 4 000 to 15 000 days
- HSM and PKI work: 500 to 2 000 days
- Re-encryption (assume 100 PB, of which 40 PB needs migration): 4 000 to 32 000 days
- Vendor management: 200 to 1 000 days
- Hardware refresh (smart cards, payment terminals, embedded devices): 2 000 to 10 000 days
- Testing and validation: 2 000 to 8 000 days
- Programme management (20%): add 3 400 to 17 000 days
Total: 20 000 to 100 000+ man-days. At £800 per day, roughly £16M to £80M+, spread over seven to ten years.
These are illustrative ranges to anchor a planning conversation, not commitments. The headline lesson is that the cost is dominated by agility refactoring and re-encryption, not algorithm changes themselves. Organisations that have done the agility work in advance, and that can delete or air-gap a meaningful fraction of their archive data, will land at the lower end of these ranges. Organisations that have hardcoded algorithm choices throughout their codebases and must re-encrypt everything at rest will land much higher.
Note to finance leaders: the cost of being late on PQC migration is not the cost of the migration itself; it is the cost of doing it under emergency conditions, plus the cost of the breach or compliance event that triggers the emergency. Emergency migration is three to five times more expensive than planned migration. The cheapest version of this work is the one that starts now.
The roadmap: parallel tracks, not a single line
In Part 1 I argued against the conventional “transit first, signing later” framing. The reason is that two distinct threat models are operating simultaneously, on different parts of the stack, and they need parallel migration tracks rather than a sequential one.
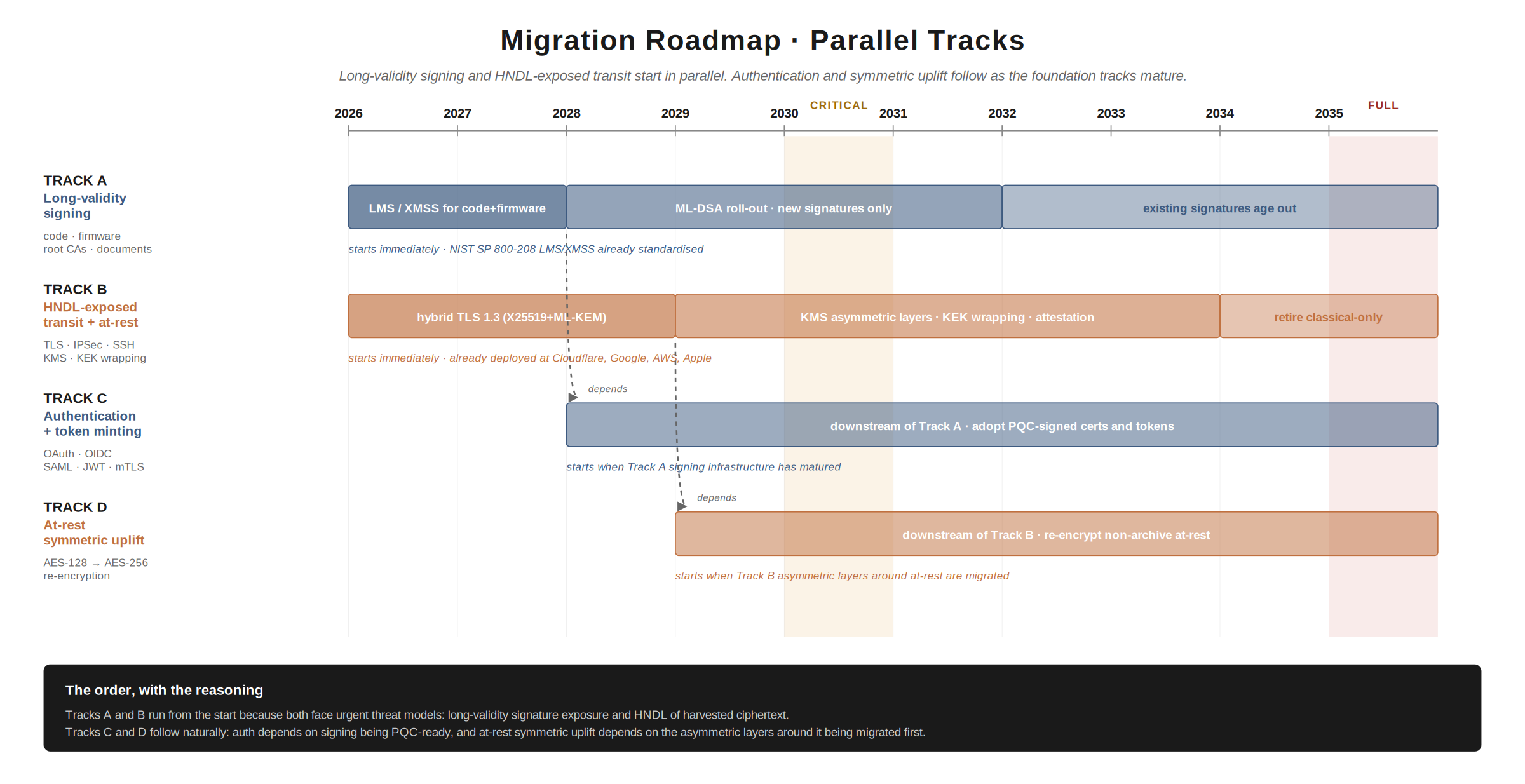
Track A: long-validity signing
Signatures applied today have validity windows that often extend past 2035, sometimes into the late 2040s. Code signing certificates, root CAs, document signatures (eIDAS qualified, notarisations), firmware signatures on devices with multi-decade operational lives. If your signature is verified in 2042 and the algorithm broke in 2032, the signature has no evidential value and the code or document it secures is repudiable.
This track moves first, in parallel with transit, because:
- Stateful hash-based signature schemes (LMS, XMSS) are already standardised in NIST SP 800-208 and are NSA-recommended for software and firmware signing under CNSA 2.0. They can be deployed today.
- ML-DSA (FIPS 204) is finalised and ready for general signing.
- The cost of signing migration is paid once for each new asset class; you don’t migrate every existing signature retroactively, you just stop minting new ones with vulnerable algorithms and let the old ones age out within their validity windows.
Track B: HNDL-exposed transit and at-rest
Data in transit (TLS, IPSec, SSH, VPN, QUIC) and data at rest with asymmetric key hierarchies (KMS-wrapped DEKs, attestation chains) face the harvest-now-decrypt-later threat directly. Hybrid TLS 1.3 with ML-KEM is already deployed by Cloudflare, Google, AWS, and Apple iMessage. The path is well-trodden for transit. At-rest is more complex because of the key hierarchy issues covered in Part 1.
This track moves first, in parallel with signing, because the longer you wait, the more harvested ciphertext sits in adversary archives, the more biometric, classified, and high-shelf-life data is exposed.
Track C: authentication and token minting
Auth flows (OAuth, OIDC, SAML, JWT signing, mTLS) sit downstream of signing migration, because they are essentially patterns of signing. Once your signing track has matured (the libraries support PQC, your certificate authorities issue ML-DSA certificates, your HSMs sign with ML-DSA), auth migration is largely a matter of adopting the signing-migrated infrastructure. It moves after Tracks A and B have matured.
Track D: at-rest data re-encryption (the symmetric layer)
Once Tracks A and B have addressed the asymmetric layers around your at-rest encryption (KMS, KEK wrapping, authentication), the remaining work is the symmetric layer itself. As I argued in Part 1, AES-256 is fine; AES-128 and weaker symmetric primitives need uplifting; this work is mostly mechanical and can be sequenced last.
Sequencing summary
Tracks A and B run in parallel from the start of the migration. Track C starts when Track A has matured to the point where signing infrastructure supports PQC end-to-end. Track D starts when Track B has matured enough that the asymmetric layers around at-rest are migrated. The whole plan converges on full PQC by 2035 (or your applicable regulatory deadline, whichever is earliest).
Where AI helps the migration, and where it shouldn’t be trusted yet
The same AI capability that’s tightening the threat window in Part 1 (Mythos finding the FFmpeg bug, the ECDLP resource compression) is the most useful single tool for parts of the migration itself. It is not, however, a complete substitute for experts in cryptography, and treating it as one will get you into trouble.
Where AI is genuinely useful
- Code analysis at scale. Walking large codebases to extract cryptographic primitive usage, identify hardcoded algorithm names, flag non-agile patterns. This is the kind of high-volume, well-bounded work where current models do well.
- Inventory generation. Producing first-pass cryptographic inventories from source code (the second source described above) is exactly the kind of workload where AI accelerates a tedious task by an order of magnitude.
- Migration mechanical work. Renaming algorithm references, updating cipher suite configurations, generating test cases for new primitives, producing migration documentation.
- Reachability analysis. Working out which CBOM-listed primitives are actually reachable from application entry points (the gap I described earlier between what libraries support and what applications use).
- Test generation. Producing comprehensive test suites for hybrid TLS and signing implementations.
Where AI should not be trusted yet
- Cryptographic protocol design. Designing or adapting protocols to use PQC primitives correctly. The size and performance characteristics of PQC primitives break assumptions in protocols designed around classical primitives, and getting this wrong introduces vulnerabilities. This is specialist work.
- Formal verification. AI assistance with formally proving security properties of new schemes is improving, but the field is not yet at the point where AI-only verification can be trusted for production systems.
- Choice of parameters and security levels. The decision to use ML-KEM-768 versus ML-KEM-1024, or ML-DSA-65 versus ML-DSA-87, is a regulatory and threat-model decision. AI can summarise the trade-offs; it should not be making the choice on its own.
- Implementation of cryptographic primitives. Side-channel-resistant implementations of ML-KEM, ML-DSA, and other primitives need expert review. AI-generated implementations are a starting point, not a deliverable.
The pattern is consistent: AI accelerates the routine and high-volume parts of the migration, freeing your specialists to focus on the design, parameter, and verification decisions where human cryptographic judgement is still essential. That changes the cost model substantially: the inventory and refactoring work in the bottom-up estimates above is significantly cheaper for organisations using AI-assisted code analysis well, and significantly more expensive for organisations that are not.
Note to engineering leaders: AI-assisted migration is going to be the difference between organisations that hit 2030/2035 milestones comfortably and organisations that don’t. Plan for it now: pilot the tooling, build the workflows, train your teams. The capability is here today.
Final Thoughts
Three things, then I’ll wrap.
Awareness, agility, and inventory are the foundation. Skip any of them and the rest of the work becomes more expensive, less effective, and harder to defend at audit. Every regulator, without exception, asks for cryptographic and data inventories first. The NIST Special Publication exists (NIST SP 1800-38), the standards are finalised (FIPS 203/204/205, SP 800-208), and the tooling is maturing rapidly. There is no excuse for not getting on with it.
The economic argument for moving early is strong, and getting stronger. Planned migration is three to five times cheaper than emergency migration. Early movers in regulated industries are picking up procurement and reputational advantage. The harvest-now-decrypt-later threat is acknowledged as present-tense by EU regulators and by the U.S. Quantum Computing Cybersecurity Preparedness Act. Every month of delay adds to your HNDL exposure for any data with shelf-life past 2030.
Parallel tracks, not a sequential plan. Long-validity signing and HNDL-exposed transit need to start in parallel, not one after the other. Authentication and at-rest follow once the foundation tracks mature. The whole thing converges on the regulatory deadlines, but it does so along multiple paths running concurrently, which is the only way the timeline arithmetic works.
Note to engineering leaders: if you take one thing from these two articles, take this. The cheapest, lowest-risk version of PQC migration is the one that starts with the inventory, builds agility into the codebase, prioritises long-validity signing and HNDL-exposed transit in parallel, treats archive data through the delete-then-air-gap-then-re-encrypt triage before re-encryption, and uses AI assistance for the mechanical work while keeping human cryptographic judgement on the design and verification work. Every regulator, every cost model, and every threat model converges on this plan. The only variable that’s still under your control is when you start.
Stay tuned!
You may also like:

Data Protection and Data Privacy - Part 2 of 2
From Principle to Practice: Privacy in the Real...

Threat Modeling Your Dependencies - Part 2
Mitigating Third-Party Component Risk: Swapping the Cancer for...

Threat Modeling Your Dependencies - Part 1
How One Bad Library Can Poison Your Entire...

Data Protection and Data Privacy - Part 1 of 2
Untangling the Confusion People often confuse these two...