Sparse or Dense? Claude Mythos, Dan Geer, and Where We Should Actually Be Spending Our Effort


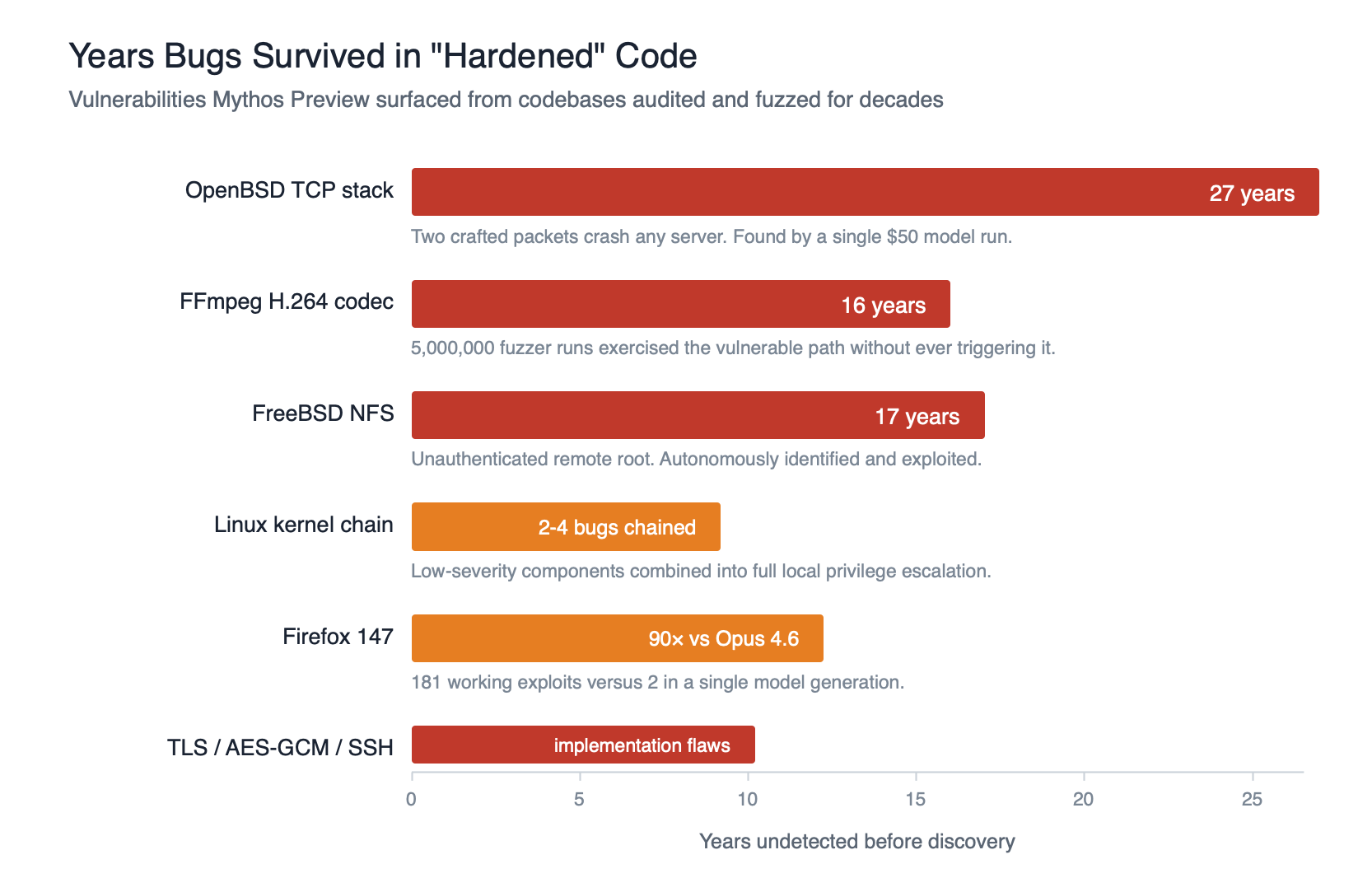
Last week, Anthropic announced Claude Mythos Preview and Project Glasswing. If you follow security news, you will have seen the headlines. Thousands of zero-day vulnerabilities found across every major operating system and web browser. A 27-year-old bug in OpenBSD’s TCP stack. A 16-year-old flaw in FFmpeg’s H.264 codec that five million fuzzer runs never triggered. Exploit chains in the Linux kernel that lead to full root. Browser exploits that chain four vulnerabilities to escape the renderer and OS sandboxes. Autonomously, with no human in the loop after the initial prompt.
The debate has, predictably, split in two directions. One camp sees this as a watershed moment: the first truly capable cyber-offensive AI, and sufficient justification for Anthropic withholding the model from general release. The other camp calls it marketing, hype dressed up as safety theatre, pointing to work from AISLE showing that small open-weights models can recover much of the same analysis once they are pointed at the right code. Both camps, I think, are missing the more interesting question.
Because there is an older debate going on underneath this one, and it is one Dan Geer raised over a decade ago.
“Are vulnerabilities sparse or dense?”
In 2015, I was working my way through an O’Reilly conference video I had bought, watching Dan Geer, then CISO of In-Q-Tel, give a talk at Suits and Spooks titled What Does the Future Hold for Cyber Security by 2020. Much of it has aged the way security predictions usually age. But one line has stayed with me for ten years:
“One of the questions we have yet to answer is whether the vulnerabilities are sparse or dense. If and only if vulnerabilities are sparse does it make sense to allocate the effort to find them or to reward those who do. If vulnerabilities are by contrast dense, so the treasure should not go to finding them but to making systems resilient to them.”
That question, sparse or dense, is the crux of how you should be investing your security budget. And for a long time, the answer was genuinely uncertain. Bruce Schneier has written about it. Errata Security’s Rob Graham proposed a third option: “vulns are sparse, code is dense.” Carnegie Mellon’s SEI has published formal analyses tying the question to Rice’s theorem and the halting problem.
But I think we can now stop arguing about it.
The verdict is in, and Geer was right
If you needed empirical proof that vulnerabilities are dense, Mythos has just delivered it at scale. Consider what the Anthropic red team reported:
- Bugs found in every major operating system and every major web browser
- A 27-year-old vulnerability in OpenBSD, arguably the most security-hardened general-purpose OS in existence, surfaced by a single autonomous run costing under $50
- A 16-year-old vulnerability in FFmpeg that automated fuzzers had exercised five million times without ever catching
- Privilege escalation chains in the Linux kernel assembled from two-to-four low-severity components
- Implementation flaws in cryptography libraries including TLS, AES-GCM, and SSH
- Over 99% of the vulnerabilities found remain unpatched as of the Glasswing announcement
This is not a trickle. This is not a single clever finding. This is a model walking into codebases that have been audited, fuzzed, and hardened for decades, and still finding bugs as though walking through an open field. If the most scrutinised software in the world still has dense vulnerabilities, the rest of our estate absolutely does. Geer was right. Schneier was right. The Errata Security compromise position — “vulns are sparse in specific well-scrutinised projects, code is dense overall” — does not survive contact with Mythos either. The specific well-scrutinised projects turned out to be dense too.
The cat was already out of the bag
Anthropic’s decision to hold Mythos back is the right one under their Responsible Scaling Policy, and I am not going to criticise the call. But let us be realistic about what holding it back actually buys us.
The capability is not in Mythos. The capability is in where the frontier has moved to. Anthropic themselves estimate similar models will appear from other labs within roughly 12 to 18 months. AISLE have already shown that 3.6-billion and 5.1-billion parameter open-weights models, models you can run on a laptop, can recover the core analysis chains of some of Mythos’s flagship findings. Their conclusion is sharp and, in my view, correct: “The moat in AI cybersecurity is the system, not the model.”
Here is what actually changed. Previous-generation models, including Opus 4.6 which was the previous public frontier, could identify vulnerabilities reasonably well but generally failed at turning them into working exploits. Exploit development was the last remaining skill that required a subject matter expert in the loop. Mythos bridges that gap, with reported 83.1% vulnerability reproduction and working proof-of-concepts on the first attempt, and a 90-fold improvement over Opus 4.6 in Firefox exploit writing.
That is the shift. Not “can AI find bugs” — we already knew it could. The new question is: can AI find a bug, write the exploit, chain it with other bugs, escape the sandbox, and send you the proof-of-concept while you are eating a sandwich in the park? That question now has a yes.
So holding Mythos back slows the attacker curve by months, not years. The defensive curve needs to move faster than that regardless.
If vulnerabilities are dense, what do we actually do?
This is where I partially agree with Geer, and partially do not.
Geer’s argument is that if vulnerabilities are dense, finding and fixing them one at a time is arithmetic futility. As Dave Aitel phrased it in a recent Lawfare piece, subtracting one vulnerability from six is a meaningful improvement; subtracting one from six thousand is not. Instead, the treasure should go to making systems resilient to vulnerabilities.
I am a firm believer in Secure by Design, and much of that belief is grounded in exactly this point. If you have to assume there will always be another vulnerability — and we now do — then your architectural decisions have to make that vulnerability’s existence survivable. The goal stops being “zero bugs” and starts being “bounded blast radius”.
In my previous two posts in this series, I spent a lot of time talking about blast radius in the context of dependencies. That framing applies just as strongly at the architectural level:
- Isolate and sandbox. Chrome’s renderer sandbox exists precisely because the browser was always going to have bugs. When Mythos chained four vulnerabilities to escape both renderer and OS sandboxes, that is frightening, but it is also evidence that defence in depth forced the attacker to do four times the work rather than one.
- Apply least privilege aggressively. A bug in a service running as an unprivileged user with a read-only filesystem is a dramatically different problem to the same bug in a root-owned process with outbound network access.
- Enforce deterministic controls on every input and every output. Zero trust, even of your own system. Every trust boundary, including the ones between your own components, needs to validate what is coming in and verify what is going out. Input validation stops exploits that depend on malformed data reaching a vulnerable parser. Output validation has become the more interesting case, particularly as AI components enter our applications. The adversarial subspace problem means that your own model, given the right input, can produce outputs you never intended: leaking training data, emitting content designed to trigger downstream systems, or exfiltrating information that should never have left the building. You cannot assume your application is not being weaponised against you. Deterministic egress checks are how you make sure your own code and your own model are not betraying you.
- Split trust boundaries. Monolithic applications, where one bug compromises everything, are the worst possible shape for a dense-vulnerability world. Microservice decomposition, isolated identity domains, and hardened trust boundaries all shrink blast radius.
- Assume compromise and plan detection. If you are going to be breached, and statistically you are, the question is whether you detect it in minutes, days, or after a third party calls you. MTTR is not just for patching. It is for incident response too.
- Manage your dependency graph. This is the whole point of the sbom-graph work and the Supply Chain Trust Score I covered in my last two posts. A dense-vulnerability world where your blast radius includes 250 downstream applications is a very different risk posture to one where that same vulnerability is contained to three.
All of that is resilience work. All of it makes Geer’s argument for putting treasure into containment rather than discovery look increasingly correct.
But there is a class of vulnerability where this strategy breaks down entirely. And I think this is where Geer’s original framing needs updating.
The foundational exception: you can’t wrap what is the wrapper
Some vulnerabilities cannot be contained by architectural resilience, because the component that is vulnerable is the thing doing the containing. Encryption is the obvious example. You cannot defence-in-depth your way out of a broken TLS implementation, because TLS is the thing your defence in depth was relying on. You cannot sandbox around a flawed AES-GCM, because the sandbox’s own secrets are protected by it. You cannot compartmentalise around a broken SSH, because SSH was how you were compartmentalising.
Mythos found implementation flaws in TLS, AES-GCM, and SSH libraries. Anthropic flagged a critical Botan certificate-bypass on the same day as the Glasswing announcement. These are not “another CVE to patch”. These are cracks in the foundation the rest of the building is standing on.
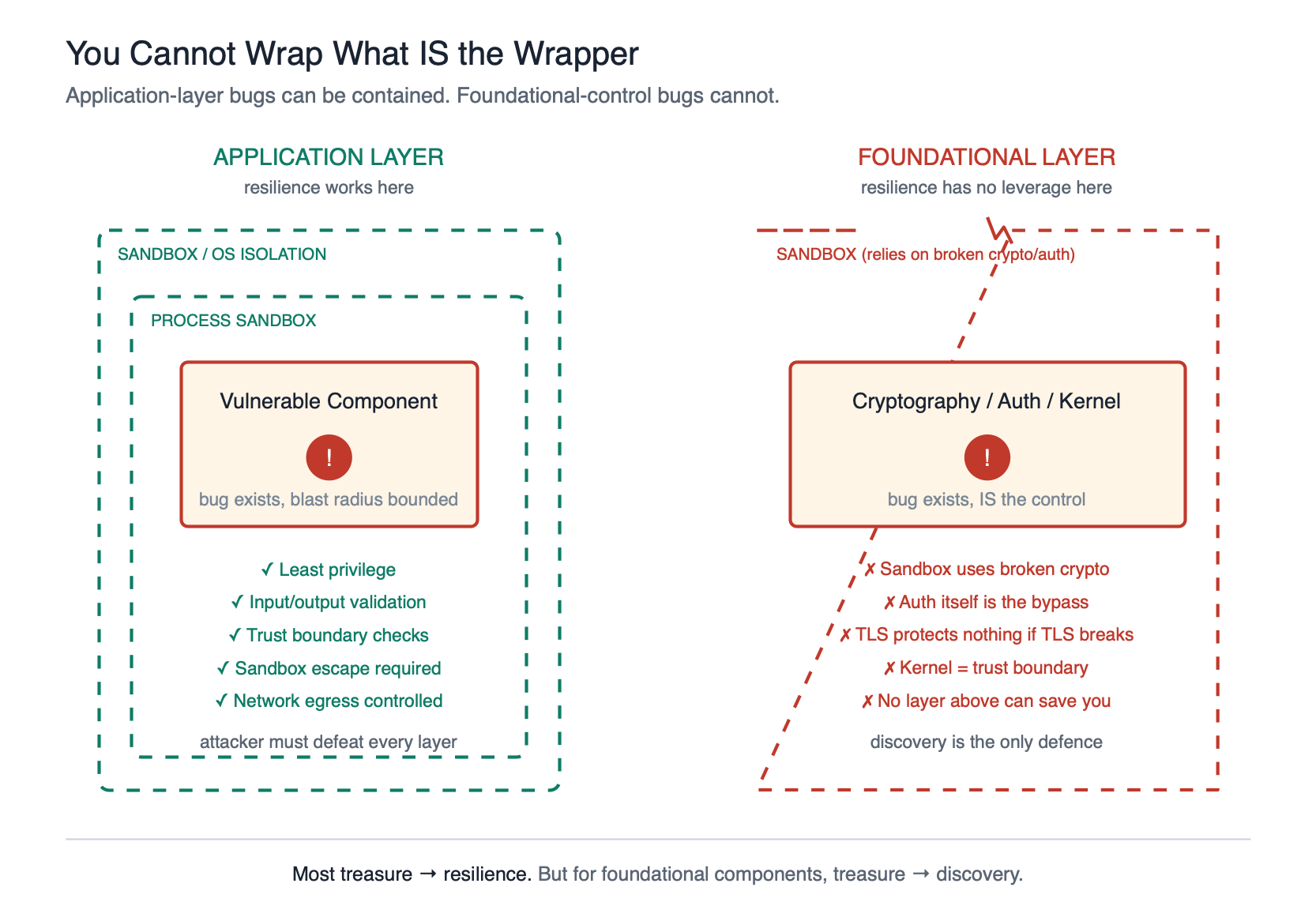
The same logic applies to authentication primitives, to kernel code, and to the sandbox implementations themselves. If the bug is in the control, there is no control to protect you from the bug.
For this class of vulnerability, Geer’s “treasure goes to resilience” argument fails, because there is no resilience without the foundational component being sound. For these, finding the vulnerability is the path. And this is exactly where a tool like Mythos, used inside Project Glasswing with organisations like the Linux Foundation, Apple, Cisco, and Microsoft, earns its keep. Getting a 27-year-old TCP stack bug out of OpenBSD is not incremental. It is structurally important, because OpenBSD is a foundation for things that themselves need to be foundations.
This is the refinement I would make to Geer’s framing. Vulnerabilities are dense in aggregate, so most treasure should go to resilience. But the small subset of foundational-control vulnerabilities deserves the opposite treatment, because resilience cannot be built on top of them.
Why this is urgent: Mosca’s theorem and the quantum clock
There is a second reason to invest in foundational hunting right now, even while prioritising resilience everywhere else. Mosca’s theorem.
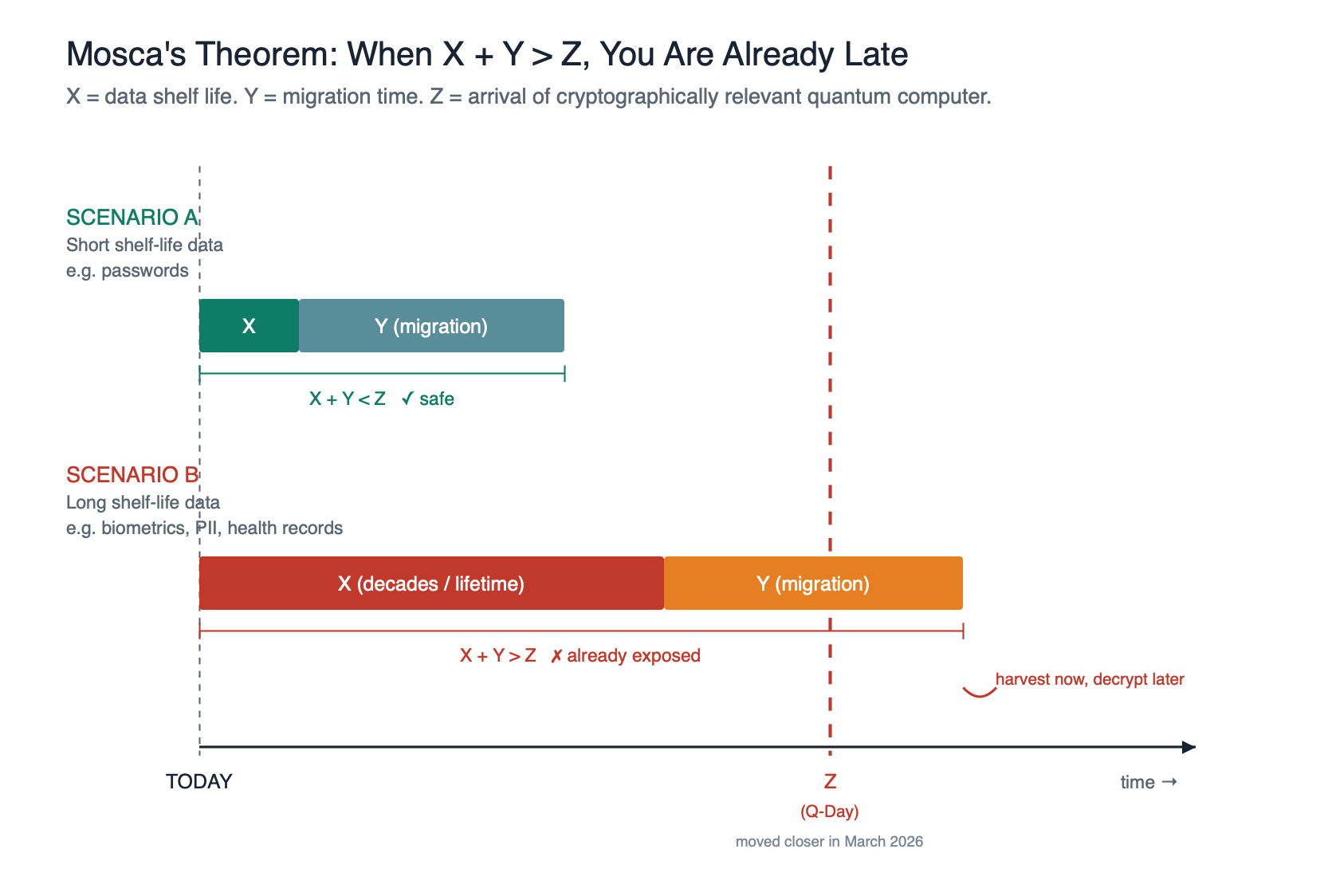
Michele Mosca’s framing is simple. Define three time horizons:
- X — the shelf life of your secrets. How long does the data you are encrypting today need to remain confidential?
- Y — your migration time. How long will it take your organisation to transition every system to post-quantum cryptography?
- Z — the collapse time. How long until a cryptographically relevant quantum computer exists that can break current asymmetric cryptography?
If X + Y > Z, you have a problem now. Because an adversary harvesting encrypted traffic today can simply sit on it until Z arrives, and then decrypt it retroactively. This is the “harvest now, decrypt later” model, and it is not hypothetical, nation-state actors are assumed to be doing it already.
Until very recently, estimates for Z varied wildly. Some said ten years, some said twenty, some said never. In the last few weeks, that picture has shifted, and not in our favour. At the end of March, two papers landed that collapsed the resource estimates for a cryptographically relevant quantum computer by an order of magnitude or more. A paper from Google Quantum AI’s Craig Gidney showed that breaking RSA-2048 may require fewer than one million noisy physical qubits, down from the roughly twenty million estimated just a few years ago. A separate Google Quantum AI paper, co-authored with researchers from the Ethereum Foundation and Stanford, put the resource estimate for breaking 256-bit elliptic curve cryptography at under 500,000 physical qubits, with a neutral-atom variant from startup Oratomic pushing that figure closer to 26,000. TIME covered the shift the week after publication. Cloudflare called it “a real shock” and pulled its post-quantum migration target in to 2029. Google set an internal 2029 deadline of its own, six years ahead of NIST’s 2035.
There is an uncomfortable twist in this, and one worth flagging explicitly. The Oratomic team has been open that AI was “instrumental” in developing their algorithm. The same technology trend that gave us Mythos is compressing the quantum timeline too. The offensive capability on classical vulnerabilities and the arrival of the machine that breaks our current cryptography are being accelerated by the same underlying thing. That is not a coincidence we should be comfortable with.
The point of Mosca’s theorem was always that you do not need to know Z precisely to know you are in trouble. You just need Y (migration time) to be uncomfortably long, which for any large organisation it absolutely is, and X (shelf life) to be uncomfortably long for some data classes, which it absolutely is for others. What has changed in the last fortnight is that Z has moved visibly closer, and the gap has narrowed.
And this is where the data classification question becomes really uncomfortable. What is the shelf life of:
- A national insurance number or equivalent: decades, effectively a person’s whole life
- A biometric template (fingerprint, face scan, iris pattern): a lifetime, you cannot rotate your face
- Genetic and health records: a lifetime, and onwards to descendants
- Financial records: years to decades, depending on regulatory retention
- A password: weeks to months, if the user is disciplined
For the first three, X is essentially infinite on human timescales. Y for a typical enterprise to migrate to post-quantum cryptography is realistically five to ten years, and for some legacy estates much longer. That means even if Z is twenty years away, we are already in trouble, because X + Y is already greater than Z for high-sensitivity PII being encrypted today.
This is why, even if we accept Geer’s argument that most vulnerability hunting is arithmetic futility, finding flaws in cryptographic implementations is a genuinely different calculation. The clock is running, the migration is slow, and the data we are protecting today has a shelf life measured in human lifetimes. The effort is worth it.
Here is where Mythos, deployed through Project Glasswing, actually matches the moment. Finding vulnerabilities in foundational crypto libraries before adversaries find them with their own frontier models, that is a defender’s dream application of this capability. That is exactly the treasure Geer was talking about, directed exactly where the density argument says it still makes sense.
Crypto Agility: How You Actually Migrate
So Z is closer than we thought, X is decades for the data classes that matter most, and Y is years for any sizeable organisation. What do you actually do?
Design for change.
NIST’s post-quantum standards (FIPS 203, 204, 205) cover the asymmetric primitives — key encapsulation and digital signatures — because that is where Shor’s algorithm does the most damage. Symmetric encryption was excluded from the migration mandate, and this sometimes gets misread as “AES is fine, no action required”. Not quite. Grover’s algorithm provides a quadratic speed-up against symmetric primitives, which roughly halves the effective security of an n-bit key against a quantum attacker. AES-256 still gives you 128-bit effective security, which is genuinely fine. AES-128 drops to 64-bit effective security, which is not. So symmetric key lengths will need to grow too, just less dramatically than on the asymmetric side.
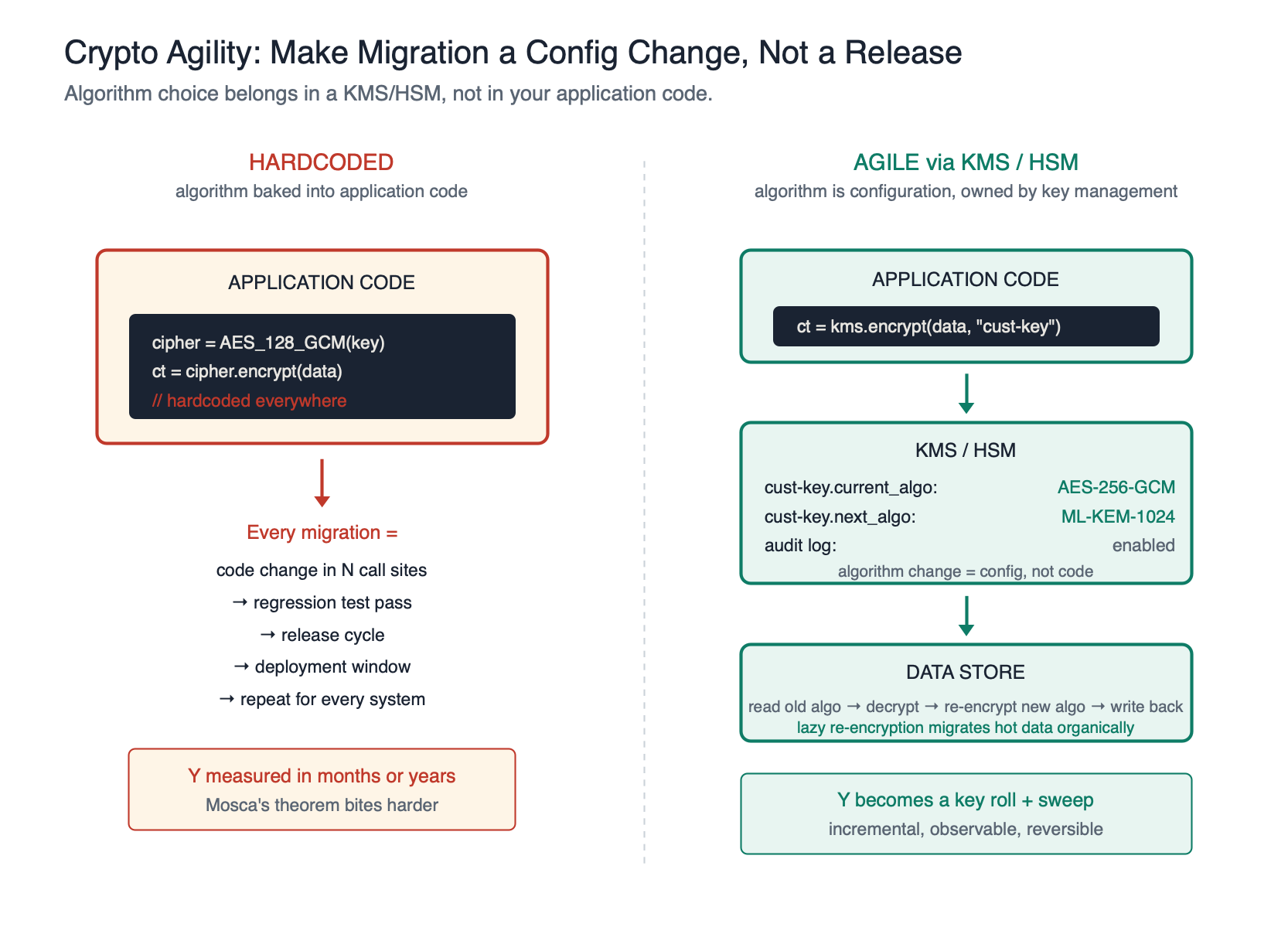
This brings us to the design principle that should be at the centre of every migration plan: cryptographic agility.
Cryptographic agility means your application can switch algorithms — not just key lengths, but entire primitive choices — without recompiling. Algorithm choice, key length, and mode should be configuration, not code. If your application has hardcoded calls to AES-128-GCM scattered through the codebase, every migration is a release cycle, a regression test pass, and a deployment window. If it has a config-driven cryptographic provider that names the algorithm and key length, every migration is a configuration change and a key roll.
Note to engineering leaders: if your codebase does not currently support agile cryptography, and most do not, that is the first piece of work to commission. It is the prerequisite for every other migration step. Without it, your Y in Mosca’s theorem expands by years.
For data at rest, there is one more practical pattern worth flagging: lazy re-encryption. Rather than attempting a big-bang re-encryption of an entire dataset, which is operationally terrifying for any large estate, you migrate opportunistically. When a record is read under the old algorithm, decrypt it, re-encrypt with the new algorithm and key, and write it back. Over time your hot data migrates organically. Cold data can be handled by a background sweep, or accepted as low priority on the grounds that nobody is reading it, until a forced cut-over date once the remaining volume is small enough to handle. The same pattern applies to password hashes, which can be re-hashed on next successful login, and to encrypted database columns.
Lazy re-encryption shrinks Y for the data that actually matters and dramatically reduces the operational risk of the migration.
Mature organisations rarely implement crypto agility in application code at all. They implement it in a centralised Key Management Service (KMS) or Hardware Security Module (HSM). The application asks for “encrypt this with the customer-data key” and does not know or care which algorithm is actually being used underneath. The KMS or HSM owns the algorithm choice, the key rotation schedule, the audit log, and the migration path. An algorithm change becomes a key-management operation, the security team rolls a new key under the new algorithm, and the next encrypt call uses it. No application change. No release cycle. No regression test pass. Combined with lazy re-encryption on read, the entire migration becomes almost entirely a key-management problem rather than an application engineering problem, which is exactly where you want it to live.
Together, agile crypto in configuration, KMS/HSM-mediated key management, and lazy re-encryption give you a migration story that is incremental, observable, and reversible, rather than a single terrifying weekend that nobody wants to sign off on.
Final Thoughts
The sparse-or-dense debate is over. Mythos was the empirical tiebreaker, and Geer won.
But I do not think the correct conclusion is “stop hunting vulnerabilities”. I think the correct conclusion is threefold:
- For most of the attack surface, treasure should indeed shift from discovery to resilience. Secure by Design, bounded blast radius, least privilege, sandboxed components, dependency-graph awareness. Treat every component as though it will one day be found vulnerable, because in a dense world, it will be.
- For foundational components — cryptography, authentication primitives, kernel code, sandbox implementations, trust boundaries — discovery is still worth the investment, because resilience has no leverage here. These must be sound or nothing above them is sound.
- Right now, for crypto specifically, Mosca’s theorem gives this investment an expiration date. The data we are protecting today has a shelf life longer than the migration time plus the quantum horizon. If you are going to point a Mythos-class model at one thing, point it here.
Project Glasswing, to Anthropic’s credit, appears to be aimed exactly at this intersection. OpenBSD, Linux kernel, crypto libraries, browsers: the foundations. That is where density is survivable only if you actively hunt. That is where you cannot wrap the problem in a sandbox, because the problem is the sandbox.
Note to security leaders: if you are reading the Mythos and Glasswing coverage and your takeaway is “we need more vulnerability scanners”, you have misread the moment. The real takeaway is this. Assume vulnerabilities are everywhere. Build systems that survive them. Reserve aggressive discovery effort for the foundational components that cannot be defended by any other means. Most of your AppSec budget should be going to architecture, not to finding more CVEs in your application code. That is a different conversation to the one most security programmes are having today.
The cat is out of the bag. Mythos proved density. Quantum is running a clock. Geer was right about where to invest, and mostly right about what to do, provided we remember the “mostly” exception. Because that exception is the thing the rest of our security stack is standing on.
Stay tuned!
You may also like:

SAST vs Claude Code Security: A Deep Dive
SAST vs Claude Code Security: A Deep Dive...