Dependency Pruning and Tree Shaking

Cutting the Dead Wood from Your Dependency Graph
In my previous posts, I covered how to threat model your dependencies and how to swap low-trust components for healthier alternatives. Both of those assume you need the dependency in question, that it’s doing real work in your application. But here’s a question that doesn’t get asked nearly enough: what if you don’t need it at all?
Most mature codebases are carrying dead weight. Dependencies that were imported six sprints ago and never cleaned up. Transitive dependencies pulled in by a library you’re using exactly one utility method from. Packages that were essential during a migration and then forgotten about when the team moved on. It’s the digital equivalent of a kitchen drawer full of takeaway menus for restaurants that closed during the pandemic, technically harmless, practically useless, and quietly contributing to the mess.
But here’s the thing, in the dependency world, dead weight isn’t harmless. Every unused dependency is an additional entry in your SBOM, an additional source of potential CVEs, an additional thing to patch when a vulnerability drops, and an additional vector for supply-chain attacks. If we learned anything from the trust scoring model, it’s that risk propagates through the graph. Removing a node from the graph doesn’t just tidy up, it eliminates an entire branch of inherited risk.
So how do we find the dead wood? That’s what this post is about. And if you’ve been following the series, you’ll recognise that the principles here are closely related to reachability analysis but applied in reverse.
Reachability in Reverse
In traditional reachability analysis, you start with a known vulnerability and ask: “Is this reachable from my application? Does my code actually exercise the vulnerable function?” You’re tracing inward, from the CVE to your call sites.
Dependency pruning flips the question. Instead of asking “am I affected by this specific vulnerability?”, you’re asking: “am I using this dependency at all? And if so, how much of it?”
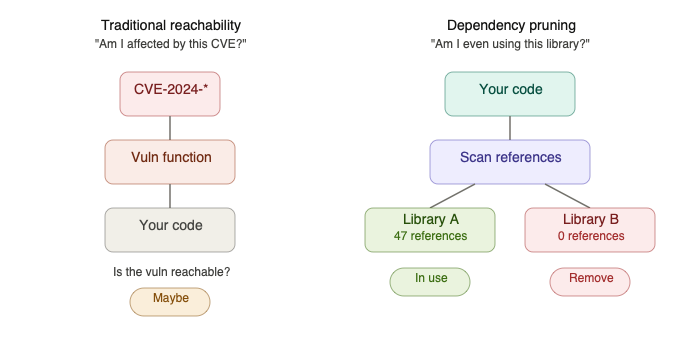
The mechanics are surprisingly similar. If you’re using a class, method, or function from a library, you’re going to be doing one of three things: importing it, injecting it, or reflecting it. That’s the universe of entry points. If none of those three things are happening for a given dependency, it’s a strong candidate for removal.
Now, those of you who’ve read my earlier posts already know I talk about reachability analysis not being infallible and that you can’t always trust it. So I won’t pretend this technique is without risks. But you can use it as an indicator of where to start pulling threads and doing the manual analysis to determine whether something can safely go.
Building the Dependency Metadata Table
Before we can analyse our own code, we need to understand what our dependencies actually offer. This is where most approaches skip a step and go straight to import scanning, which is fine for the obvious cases but misses the subtler ones.
For each third-party component in your dependency list, we want to build a metadata table of entry points. Think of it as an inventory of everything the library exposes:
- Public and protected classes:- the things you’d directly instantiate or extend
- Public methods and functions:- the API surface you’d call
- Namespaces and module paths:- critical for catching wildcard imports (
from library import *) and sub-module usage - Interfaces and abstract base classes:- because your code might implement an interface defined in a dependency without ever importing a concrete class from it
- Annotations and decorators:- particularly relevant in frameworks like Spring, where
@Autowired,@Bean, and@Componentwire dependencies without explicit import statements
This metadata extraction is language-specific, but the principle is universal. In Java, you’re scanning the public API of JAR files, classes, methods, annotations. In Python, you’re inspecting the module’s public surface via AST analysis or the package’s __init__.py exports.
The key insight is that this metadata gives us a lookup table. Instead of asking “does my code import library X?”, we can ask the much richer question: “does my code reference anything from library X’s public surface, directly, transitively, or reflectively?”
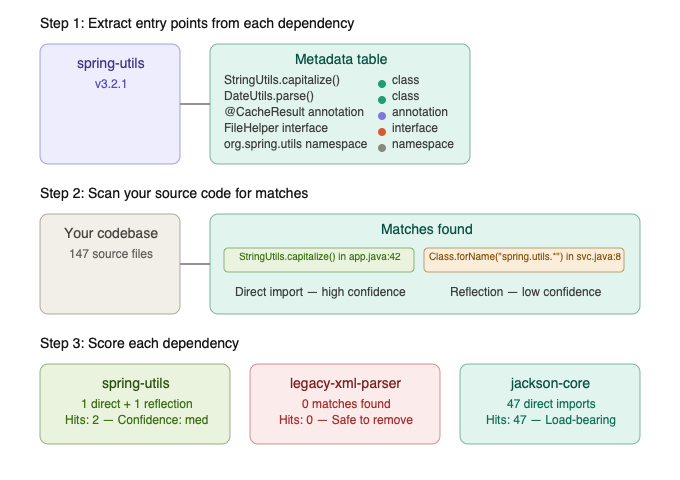
Analysing Your Code Against the Table
With the metadata table built, we scan our own codebase. For every source file, we’re looking for references that match entries in the table. The type of reference determines our confidence level:
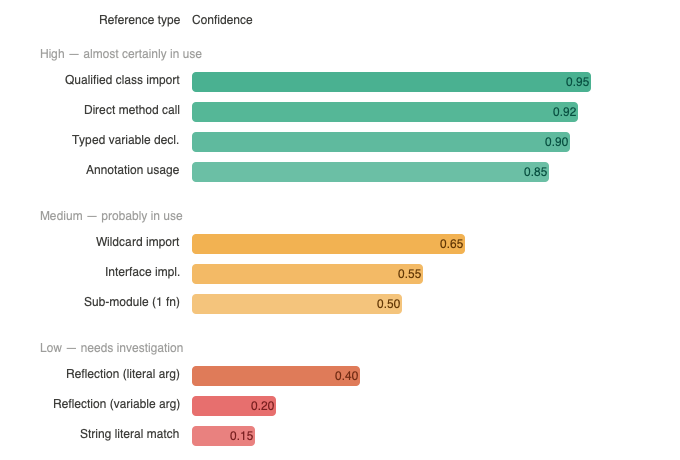
High confidence:- almost certainly in use:
- A fully qualified class import that matches a class in the metadata table (
import com.fasterxml.jackson.databind.ObjectMapper) - A variable declaration typed to a class from the dependency
- A direct method call on an instance of a dependency class
- An annotation from the dependency applied to a class or method (
@JsonProperty,@Autowired)
Medium confidence:- probably in use, worth verifying:
- A wildcard import that matches a namespace in the metadata table (
from requests import *) - A sub-module import where only one function is used
- A class implementing an interface defined in the dependency
Low confidence:- needs manual investigation:
- An interface from a core library (like
java.io.Serializable) that happens to be implemented by a class in the dependency, this is a weak signal at best - A string literal that matches a class name, which could indicate reflection or configuration-driven usage
- A pattern match in a reflection call (
Class.forName(variable)) where the variable might resolve to something in the dependency
For every match we find, we increment two counters: a hit count (how many references exist) and a cumulative confidence score. This gives us two dimensions of understanding: how integral the dependency is to the application, and how certain we are about that assessment.
A dependency with 47 high-confidence hits is clearly load-bearing. A dependency with a single low-confidence hit, say one string literal that might be a reflection target, is a very different proposition.
The Reflection Problem
I want to call out reflection specifically because it’s where most naive dependency scanners fall over.
In Java, Class.forName(), ClassLoader.loadClass(), and the entire Spring dependency injection mechanism mean that a dependency can be deeply woven into your application without a single explicit import statement in your source code. In Python, importlib.import_module(), __import__(), and framework-level magic like dependency-injector containers create the same problem.
Our approach handles this by treating reflection calls as pattern-matching opportunities rather than binary signals. When we encounter a reflection call:
- If the argument is a string literal that matches an entry in our metadata table — that’s a high-confidence hit. We know exactly what’s being loaded.
- If the argument is a variable or expression, we flag it as
UNCERTAIN. Something in the codebase might be using the dependency via reflection, and a human needs to look at it. - If we find no reflection references and no imports, the dependency is a candidate for
SAFEclassification.
This is the same classification model we use in Depruner, the dependency analysis tool I’ve been building alongside this series. The three-tier confidence system, SAFE, UNCERTAIN, IN_USE, exists precisely because the real world doesn’t give us binary answers. And I’d rather flag something as uncertain and have an engineer spend five minutes verifying it than silently recommend removing a dependency that breaks the build.
What You’re Really Building: A Lightweight Call Graph
If you step back and look at what we’ve described, we’re essentially constructing a basic call graph but a deliberately shallow one. We don’t need the full picture. We don’t need to trace every method call through every stack frame. We need indicators.
Think of it as triage, not diagnosis. The call graph tells us:
- This dependency is heavily referenced:- 50+ high-confidence hits across 12 source files. It’s clearly doing real work. Move on.
- This dependency has moderate usage:- a handful of references, mostly in one module. Worth investigating but probably needed.
- This dependency has a single reference:- one utility method call in one file. Now we’re interested.
- This dependency has zero references:- no imports, no reflection, no annotations. Flag it as safe to remove.
That last category is the low-hanging fruit, and in my experience, most mature codebases have more of it than anyone expects. But it’s the second-to-last category that often delivers the biggest wins.
The One-Method Dependency: Where Real Value Hides
Here’s the scenario that should make your ears prick up. Your analysis shows that you’re importing a Spring utility library for a single method, let’s say a string manipulation function. That’s the only reference in your entire codebase. One method. One call site.
But that utility library has ten transitive dependencies of its own. Ten additional entries in your SBOM. Ten additional sources of potential vulnerabilities. Ten additional things your trust scoring model is now evaluating, and if any of them score poorly, dragging down the effective trust score of every application upstream.
All for a string manipulation function you could implement in fifteen lines of code.
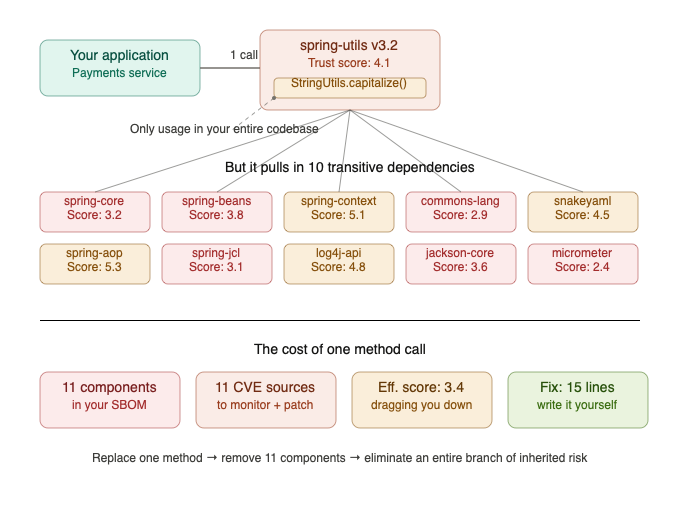
This is where dependency pruning connects directly to the threat modelling and trust scoring work from the previous posts. The cost-benefit calculation writes itself:
- Cost of keeping the dependency: ongoing vulnerability exposure across ten transitive components, MTTR delays when CVEs drop, potential waiver fatigue, reduced effective trust scores
- Cost of replacing it: fifteen minutes to write a utility function (or find a more targeted library), run the tests, deploy
When you frame it that way, the decision isn’t close. But without the analysis to identify these one-method dependencies, you’d never know the opportunity existed. You’d just keep patching CVEs in a library you barely use and wondering why your supply-chain risk metrics aren’t improving.
Connecting to Trust Scores and Business Risk
If you’ve implemented the Supply-Chain Trust Score from the first post in this series, dependency pruning becomes even more powerful. Every dependency you remove improves the effective trust score of everything upstream, automatically, through the propagation model.
Remove a low-scoring transitive dependency and the leaf library that depends on it sees its effective score improve. That improvement propagates to every internal component that depends on the leaf library. Which propagates to every application that depends on those components. One removal, cascading benefit across the graph.
And if you’ve connected trust scores to monetary risk exposure, which I strongly recommended in the first post, you can now quantify the business value of a dependency removal. Not just “we removed a library” but “we reduced £2.3M of aggregate risk exposure across 14 applications by removing a dependency that was contributing one utility function and ten transitive components.”
That’s a story you can tell to a board. That’s a metric that justifies the engineering time.
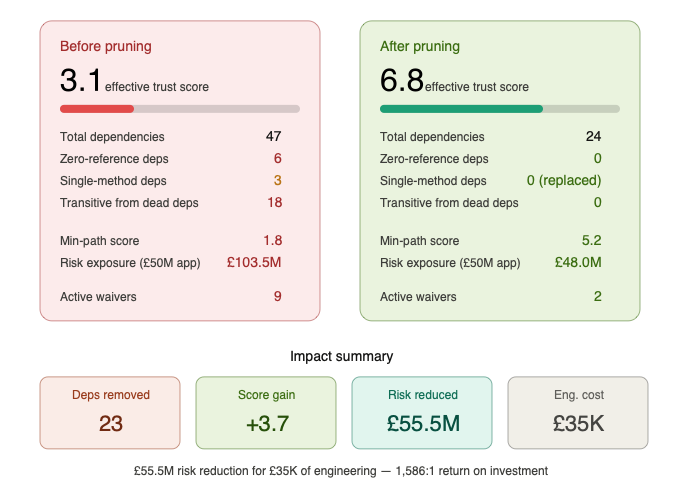
But Here’s Where My Concern Arises
I want to be honest about the limitations, because overselling this approach would be irresponsible.
False negatives are the real danger. If the analysis misses a reference, because it’s hidden behind reflection, loaded via configuration, or wired through a framework mechanism we didn’t account for, and someone removes the dependency based on our SAFE classification, the application breaks. This is why the confidence model exists, and why UNCERTAIN is a valid classification. But even with the best heuristics, there will be edge cases the tooling misses. Human review remains essential for anything the tool flags as safe to remove.
Build-time and test-time dependencies are tricky. A dependency might have zero references in your production source code but be critical for your test suite, your build plugins, or your annotation processors. The analysis needs to be scoped appropriately, or at least, flag build-time dependencies separately from runtime ones.
The metadata extraction isn’t trivial. Building an accurate entry-point table for a third-party library requires understanding its public API surface, which varies by language, build system, and packaging convention. A Java JAR is relatively self-describing. A Python package with lazy imports and __getattr__ magic is considerably harder to inventory accurately.
Transitive dependencies add complexity. When we say “you’re only using one method from library X”, we also need to check whether any of library X’s other dependants in your ecosystem are using more of it. Removing it from one application is fine; removing it from a shared internal library that’s consumed by applications that do use it heavily is a different calculation entirely.
The Practical Playbook
So how would I recommend approaching this?
Step 1: Start with your highest-risk applications. Use the trust scoring model to identify the applications with the lowest effective scores and the highest business value. These are where dependency pruning will deliver the most risk reduction per hour of engineering effort.
Step 2: Run the analysis. Build the metadata tables for all declared dependencies, scan the source code for references, and classify each dependency. Focus on the SAFE and low-hit-count categories first.
Step 3: Investigate the zeros. Dependencies with zero references across the entire codebase are your strongest removal candidates. Verify with the team that they’re not build-time or test-time dependencies, then remove them and run the full test suite.
Step 4: Investigate the ones. Dependencies with a single reference, especially a single utility method call, are your highest-value swap candidates. Can you replace the call with a local implementation or a more targeted library? If the single-method dependency is dragging in ten transitive components, the answer is almost certainly yes.
Step 5: Measure the impact. After each removal or swap, re-run the trust scoring pipeline. Verify that effective scores improved as expected. Quantify the risk reduction in business terms. Report upward.
Step 6: Automate the cycle. Integrate the analysis into your CI pipeline so new unused dependencies are flagged before they accumulate. Prevention is always cheaper than remediation.
What Needs More Thought
There are areas where this approach needs further development, and I’d rather be upfront about them than pretend we’ve solved everything.
Cross-language analysis. A Java application with a Python ML service and a JavaScript frontend has dependencies in three ecosystems. Analysing each in isolation misses the interactions between them. A dependency that appears unused in the Java layer might be critical for the Python service that the Java application calls at runtime. Cross-ecosystem dependency pruning is a hard problem that nobody has fully cracked yet.
Framework-specific heuristics. Every framework has its own magic. Spring has @ConditionalOnClass and auto-configuration. Django has INSTALLED_APPS. Flask has blueprint registration. The analysis engine needs framework-aware plugins, and building those for every framework in every language is a substantial ongoing effort.
The cultural challenge. Engineers are, reasonably nervous about removing dependencies. “It works, don’t touch it” is a deeply ingrained instinct, and it’s not entirely wrong. The confidence model helps, but ultimately you need a culture where dependency hygiene is valued and where the team trusts the tooling enough to act on its recommendations. That trust is earned incrementally, not declared.
Final Thoughts
The dependency graph isn’t just a risk surface, it’s an efficiency surface. Every unnecessary dependency is a tax on your security team’s time, your CI pipeline’s speed, and your application’s attack surface. Dependency pruning, guided by the same reachability principles that power vulnerability analysis, gives you a systematic way to identify and eliminate that tax.
Combined with the trust scoring and alternative discovery approaches from the previous posts, you now have a complete lifecycle for supply-chain risk management: score your dependencies, swap the dangerous ones, and prune the unnecessary ones. Each step reduces risk, improves your effective trust scores, and frees up engineering effort that would otherwise be spent fighting fires.
The dead wood in your dependency graph isn’t going to remove itself. But with the right analysis, the right confidence model, and the right connection to business risk, you can make a compelling case for cutting it. And every branch you cut is one less thing that can catch fire.
Note to engineering leaders: Pick your three highest-value applications. Run a dependency analysis. I’d bet at least 10% of the declared dependencies have zero references in your source code, and at least one of them is dragging in a chain of transitive components that are actively hurting your trust scores. Find it. Remove it. Measure the improvement. Then do it again.
Stay tuned!