Why SAST is Broken!


Why SAST is broken, and how it could be addressed
Source
At first glance, Static Application Security Testing (SAST) appears straightforward because it analyzes human-readable source code. However, it faces significant limitations. A typical SAST scanner can only analyze the code within the current project, often missing the broader context of dependencies, especially internal “inner source” or second-party components.
While many popular third-party libraries are pre-analyzed, enabling tools to flag dangerous interactions, internal libraries often lack this context. For example, consider an internal SDK used for database communication.
Most SQL injection vulnerabilities are detected when a scanner observes a concatenated string being passed to a known query execution method. However, if the query execution occurs within an opaque internal library, the scanner loses visibility into the data flow. Without confirming that the concatenated string reaches a database sink, the tool fails to flag the vulnerability.
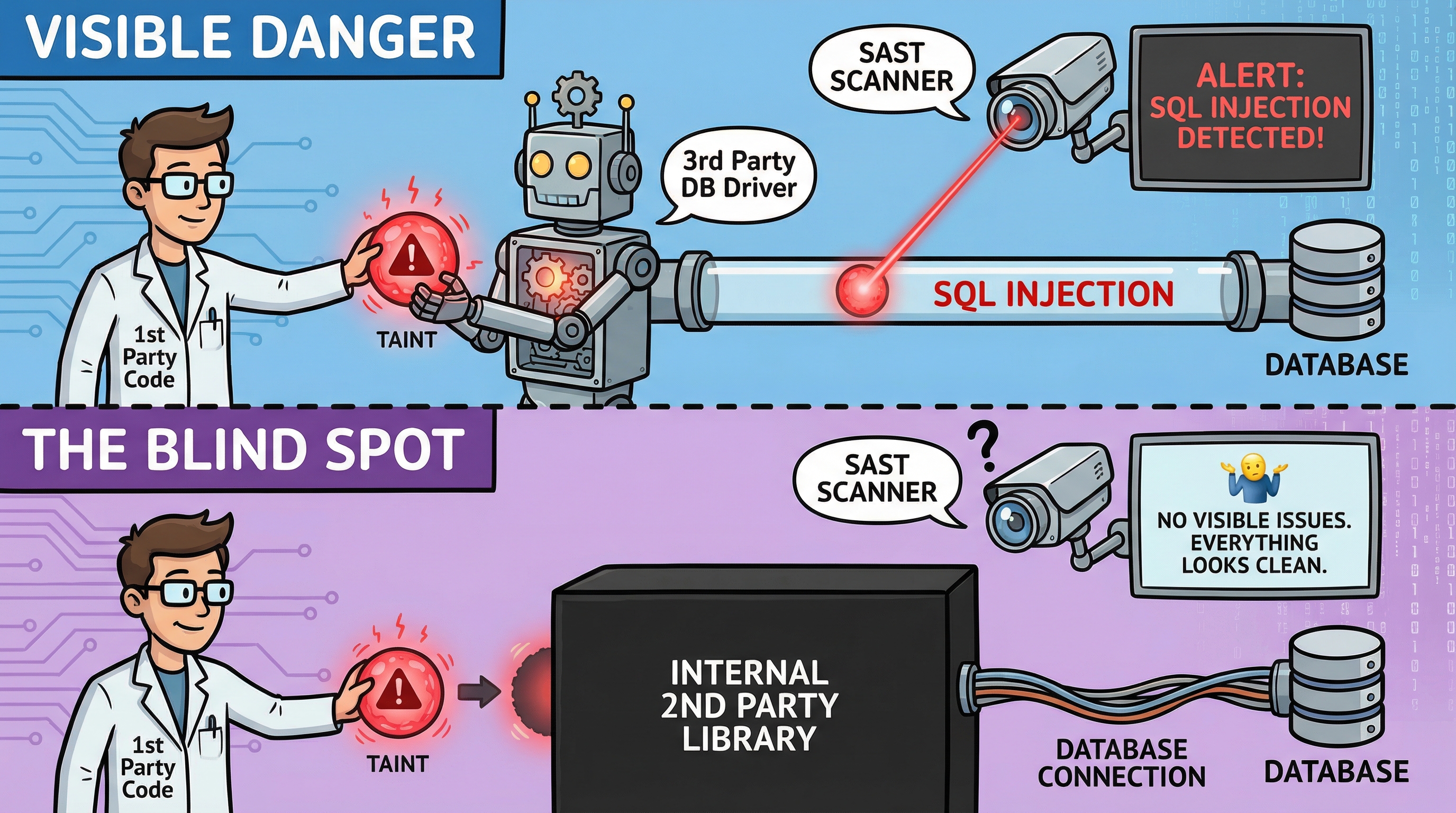
This issue, known as cross-repo or cross-component taint, highlights a critical blind spot in SAST tools. Metadata about internal components could address this issue. For instance, scanners could include metadata signaling that an entry point or interface contract leads to a sink (e.g., database or shell) that doesn’t sanitize input. This would allow developers to identify vulnerabilities requiring sanitization.
Note to SAST vendors: Build a metadata repository for internal libraries, similar to what exists for third-party libraries. Automating this process isn’t overly complex, and given the high costs of SAST tools, this should be a standard feature.
Binary
Binary analysis offers a potential solution to the cross-repo taint issue by analyzing the entire system, including internal libraries. This approach would detect vulnerabilities like SQL injection because it can trace the full data flow. However, it introduces a new problem: noise. Binary analysis identifies vulnerabilities within second-party code that may not be directly related to the first-party project.

For example, if an internal library contains vulnerabilities, every project using that library will report the same issues. This creates duplicate results, overwhelming developers with irrelevant findings. Teams working on the first-party project may not have the authority or expertise to fix vulnerabilities in the second-party library.
Note to SAST vendors: Implement cross-project data aggregation to eliminate duplicates. Allow filtering to focus on vulnerabilities directly related to the project’s code or its interactions with third-party components. Developers don’t need to see issues they can’t fix—reduce the noise and let them focus on actionable insights.
General Failings of SAST
The root cause of many SAST limitations is the lack of context. Without understanding the environment in which the code operates, SAST tools often produce false positives. For example:
- Path Traversal False Positives: A command-line utility that accepts a file path as an argument might be flagged for path traversal vulnerabilities. However, if the script runs with the user’s existing permissions, the user already has access to the file system. Flagging this as a vulnerability is illogical.

- CSRF False Positives: SAST tools often flag API endpoints for missing Cross-Site Request Forgery (CSRF) protection, even when the endpoints are not accessed via a browser or another endpoint. In such cases, CSRF protection is unnecessary.
Note to SAST vendors: Context is critical. Tools must account for the environment and usage patterns to reduce false positives and improve accuracy.
Benchmarking SAST Tools
To determine which SAST tool best meets your needs, benchmarking is essential. Consider the following factors:
- Accuracy: Precision and recall.
- Performance: Can it run efficiently in your CI/CD pipeline?
- Developer Experience: Does it avoid breaking builds due to false positives?
- Ease of Onboarding: How simple is it to onboard projects?
- Ease of Integration: Does it integrate with your pipeline, version control, and IDEs?
- Clean as You Code: Can it catch issues early in the development process?
- Reporting: Does it provide actionable insights out of the box?
- API Support: Can you automate workflows as needed?
- UI: Does it offer a user-friendly interface for pull requests, web dashboards, and IDE plugins?
- AI Workflow Integration: Does it integrate with AI-driven workflows (MCP)?
Measuring Accuracy
Accuracy is a critical metric, but vendor-provided statistics are often unreliable. To evaluate accuracy independently, follow this process:
- Select Languages: Choose the programming languages you want to evaluate (e.g., Java, Python, Go, JavaScript).
- Define Project Types: Decide on the types (e.g., front-end, back-end) and sizes (e.g., monolith, microservices) of projects to analyze.
- Choose Repositories: Select repositories with known security fixes.
- Identify Vulnerabilities: Review commit messages to identify security fixes and check out the previous commits containing vulnerabilities.
- Run Scans: Scan the repositories with all the SAST tools you want to evaluate.
- Aggregate Results: Assume that vulnerabilities flagged by all tools are correct. Use this as the baseline for comparison.
- Review Results: Manually review remaining results to identify true and false positives. Note: Remember and this is fundamental a True Positive missed by one tool is a False Negative for another tool if it wasn’t caught.
- Each additional True Positive should be added to the baseline, to get the number of vulnerabilities available. This is not a precise number because all tools may have missed issues but it’s sufficient for a comparison. True Positives + False Negatives should equal this number.
- Calculate Metrics: For each tool, calculate precision, recall, and the F-score for each severity using the following formulas:
- Precision: $$\text{Precision} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}}$$
- Recall: $$\text{Recall} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}$$
- F-Score: $$F = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}$$
- Compare Tools: Use the F-scores by severity to compare the accuracy of each tool.
Summary
SAST tools are invaluable for identifying vulnerabilities, but they are far from perfect. Their limitations, such as lack of context, inability to handle cross-repo taint, and excessive noise, can hinder their effectiveness.
Vendors must address these issues by improving metadata handling, enabling cross-project data aggregation, and incorporating contextual analysis.
Until then, benchmarking the tools yourself to find the least broken option remains the best approach for organizations.
You may also like:

SAST vs Claude Code Security: A Deep Dive
SAST vs Claude Code Security: A Deep Dive...