Data Protection and Data Privacy - Part 1 of 2


Untangling the Confusion
People often confuse these two topics. There’s a common belief that once someone consents to you using their data you can use it for whatever you want, as long as you don’t disclose it publicly. That you should protect their data while it’s in your custody, but often without really knowing what should be considered personal data in the first place. So let me dispel a few myths.
In my recent two-part series on getting Post Quantum Cryptography ready, I touched on the need for a data inventory and a cryptographic primitive inventory. And in the supply chain series before that, we built up a model of how risk propagates through your dependency graph. Both of those threads converge here. You can’t protect data you haven’t inventoried, you can’t claim to respect privacy if your cryptographic primitives are broken, and you can’t trust your supply chain to handle PII safely if you don’t know what’s lurking at depth 5.
In this first part I’ll cover what personal data actually is, what data protection means across the full data lifecycle, what data privacy means as a distinct concept, the privacy principles that underpin both, and how Privacy by Design ties the two together. In Part 2, we’ll get into the practice: threat modelling for privacy, dark patterns, data subject rights, the technical controls that matter, and what a proper data inventory looks like.
Let’s start with the foundation that almost everyone gets wrong.
What Actually Counts as Personal Data?
When I talk to engineering architects, the first question that comes up is almost always: “is this PII?” And the answer almost always surprises them.
Personal data is not just names, email addresses, and ID numbers. The UK GDPR (and the EU GDPR before it) defines personal data as any information relating to an identified or identifiable natural person. That last word, identifiable, is doing a lot of heavy lifting.

Direct identifiers
These are the obvious ones: name, email address, phone number, national insurance number, passport number, customer account ID. If you have this datum, you know who the person is.
Indirect identifiers (quasi-identifiers)
Here’s where it gets interesting. A postcode on its own doesn’t identify anyone. A date of birth doesn’t identify anyone. Gender doesn’t identify anyone. But Latanya Sweeney’s research showed that for the US population, the combination of ZIP code, date of birth, and gender uniquely identifies roughly 87% of people. Quasi-identifiers compose. Three pieces of “harmless” data can be more identifying than a name.
This is the bit engineers consistently miss. Your analytics database might have no names in it, but if it has IP addresses, browser fingerprints, geolocation, and a behavioural timeline, you’re holding personal data.
Special category data
Under UK and EU GDPR, certain types of data are designated as special category and carry stricter processing requirements: racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, genetic data, biometric data used for identification, health data, and data concerning a person’s sex life or sexual orientation. Processing this data lawfully requires a separate Article 9 condition on top of the standard Article 6 lawful basis.
Inferred data
This is the category most engineers don’t even know exists. If you collect a user’s purchase history and your model infers that they’re pregnant, that inference is personal data. If your recommendation engine concludes that a user is likely to be depressed and serves them ads accordingly, that conclusion is personal data, and quite possibly special category health data. You created it, but it’s still theirs.
The Court of Justice of the European Union confirmed in OQ v. SCHUFA Holding (2023) that automated profiling outputs are personal data subject to data subject rights. You can’t hide behind “we didn’t collect that, we generated it.”
Pseudonymous is not anonymous
One more critical distinction. Pseudonymous data (where direct identifiers have been replaced with a token, but the mapping still exists somewhere) is still personal data. Only truly anonymous data, where re-identification is genuinely impossible, falls outside data protection law. As Sweeney’s work demonstrated, true anonymisation is harder than most engineers think. We’ll come back to this in Part 2.
What is Data Protection?
Data protection is about ensuring data is not disclosed to people it shouldn’t be, and this matters at every stage of the data lifecycle. Not just at rest. Not just in transit. Throughout.
The Data Lifecycle
The data lifecycle has the following phases:

Plan. Before you collect anything, decide what you’ll collect, what you actually need it for, how long you’ll keep it, who will have access, and how it will be governed. If you don’t know these answers before collection, you’re already in trouble.
Acquire / Collect. Gather the data from internal and external sources. The app or website collecting the data must not let other users see it, must not have vulnerabilities that let attackers harvest it, must not redirect users to malicious sites, and must encrypt the data in transit so nobody can snoop on the wire. Consent must be captured and recorded together with the version of the notice that was shown.
Store / Manage. Encrypt at rest using algorithms that will still be considered secure five years from now (recall the PQC discussion from the last series). Apply access controls at the row, column, and field level as appropriate. Mask or tokenise sensitive fields. Keep audit logs of who accessed what, and ensure those logs themselves don’t leak the data they’re auditing.
Use / Analyse. Apply the principle of least privilege to data, not just to user accounts. Use pseudonymisation for analytics where the analyst doesn’t need to know who the data belongs to. Be ruthless about what enters logs, error reports, and observability data: stack traces with PII in them are one of the most common sources of accidental disclosure.
Share / Distribute. When data is shared with third parties, processors, or other parts of the business, the legal basis and contractual terms must be in place first. Data Processing Agreements (DPAs) under GDPR Article 28 are not paperwork, they’re the mechanism that propagates your obligations down the chain. And every API that exposes data is a sharing point, whether you think of it that way or not.
Archive / Retain. Data you no longer actively use but still need to keep (for legal, regulatory, or business reasons) should be moved to colder, more tightly controlled storage. Retention schedules must be defined and enforced. “We keep everything forever just in case” is not a retention policy, it’s a future breach.
Dispose / Destroy. When the retention period ends, the data must be deleted. Properly. This includes backups, replicas, caches, search indexes, and analytics aggregates derived from it. The right to erasure (more on this in Part 2) makes this not just good hygiene but a legal obligation.
A vulnerability or process failure at any one of these phases is a data protection failure. You can have perfect encryption at rest and still leak PII through your error logs. You can have flawless TLS and still lose data because your archive bucket was misconfigured. The chain is only as strong as its weakest phase.
What is Data Privacy?
Data privacy is something different. Where data protection asks “is the data secure?”, privacy asks “is the data being used appropriately?”
Let me give you a concrete example. If I order something on a website and they ask me for my phone number so the courier can get hold of me if they can’t find the address, that number should only be used for that purpose. If three months later they ring me up to sell me insurance, they’ve protected my data perfectly well (nobody else got it) but they’ve completely failed on privacy (they used it for something I didn’t agree to).
Even if I publish my phone number openly for everyone to see, but I specify the purpose for which it can be used, it should only be used for that purpose. No ifs, no buts. If you use my information in any way that wasn’t agreed upon, you’re not respecting my privacy.
And here’s the one that catches people out: if my data is leaked and you buy it from a broker, that doesn’t grant you any rights to use it. Your purchase is a transaction between you and the broker. It has nothing to do with my consent, my purpose limitation, or my rights as the data subject. Buying stolen goods doesn’t make them yours, and buying leaked data doesn’t make it yours either.
Privacy as Contextual Integrity
Before getting into the principles themselves, there’s a framework that explains why they exist and helps reason about privacy questions the principles alone don’t fully answer.
Helen Nissenbaum’s theory of Contextual Integrity, set out most fully in her 2010 book Privacy in Context, argues that privacy is not about secrecy or control over information in the abstract. It is about whether information flows in ways that match the norms of the context in which it was originally shared.
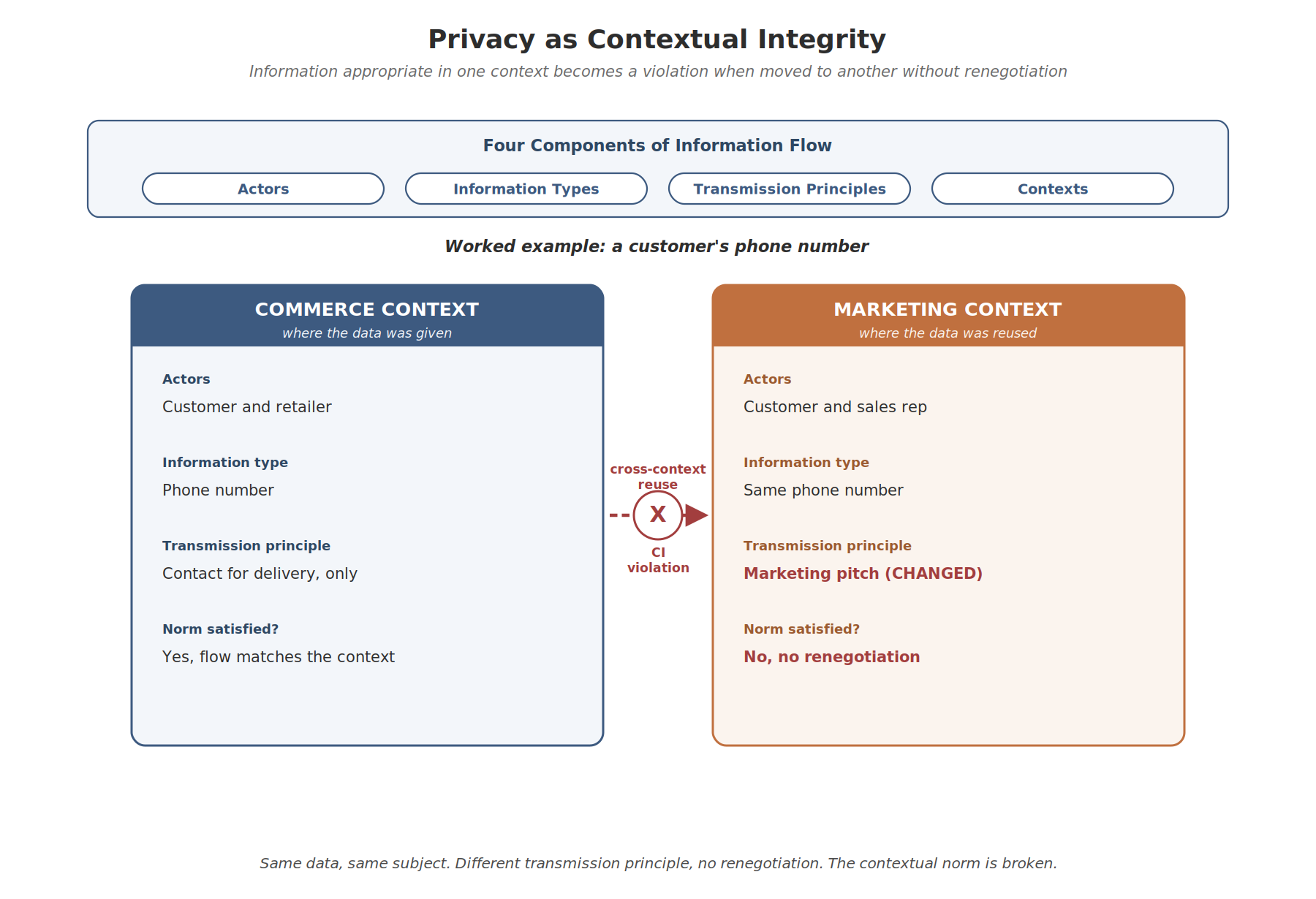
The framework has four moving parts:
- Contexts are distinct social spheres, each with its own norms: healthcare, friendship, employment, commerce, religion, education, financial services.
- Actors are the sender, the recipient, and the subject of the information being shared.
- Information types are the categories of data being communicated.
- Transmission principles are the rules governing how the data may flow: confidentiality, reciprocity, custom, professional duty, consent, contract.
A privacy violation occurs when any of these is changed without the subject’s understanding or agreement. The phone number example I gave earlier is a textbook case. You shared the number in a commerce context, for a specific transmission principle (the courier needs to reach you about a delivery). Three months later they use it for marketing. The actors haven’t changed. The information type hasn’t changed. The transmission principle has, silently. That’s the violation, and it’s the one most easily described in CI terms even when no traditional privacy boundary has been breached.
CI also explains why purchased breach data has no legitimacy. The original context in which that data was given has nothing to do with the purchaser. No transmission principle ever linked the data subject to the broker’s customer. Whatever contract the broker and the buyer signed, the contextual flow norms had already been broken the moment the data left the original context. You cannot retroactively grant yourself the right to use information by paying someone else for it.
CI is not a substitute for the privacy principles or for data protection law. It is the conceptual framework that makes sense of why both exist. When you are stuck deciding whether a new use of data is acceptable, CI gives you a way to interrogate it. In what context was this data given? What were the norms of that context? Has anything in this proposed use changed the actors, the information type, or the transmission principle? If yes, you have either renegotiated openly with the subject or you have violated their privacy. The middle ground (hoping nobody notices) is what we usually call a dark pattern, and we’ll get to those in Part 2.
The Privacy Principles
The privacy principles are the foundation on which both data protection law and ethical data handling stand. They originate in the OECD Privacy Guidelines (first published in 1980, revised in 2013), and have been incorporated, with variations, into the UK GDPR, the EU GDPR, and most modern privacy regimes including California’s CCPA and CPRA.

Lawfulness, Fairness and Transparency
Processing must have a lawful basis (consent, contract, legal obligation, vital interests, public task, or legitimate interests under GDPR Article 6). It must be fair, which means it shouldn’t have unjustified adverse effects on the data subject. And it must be transparent: the data subject should know what’s happening with their data without having to dig for it. A 2,000-word privacy notice written in legalese is technically transparent and practically opaque, which is the opposite of the principle’s intent.
Collection Limitation (Data Minimisation)
Collect only what you actually need for the specified purpose. Not what you might find useful one day. Not what your data science team would like to play with. If you don’t need it for the stated purpose, you don’t take it. This single principle would eliminate most of the data hoarding endemic in modern tech.
Purpose Limitation (Use Limitation)
Data collected for one purpose must not be used for an incompatible purpose without a fresh lawful basis. The phone number example earlier is a textbook purpose limitation violation. If you collected an email for transactional notifications, you can’t repurpose it for marketing without a new consent.
Data Quality and Accuracy
Personal data must be accurate and, where necessary, kept up to date. Inaccurate data must be corrected or erased. This isn’t just about your CRM having the right address: if your fraud detection model is acting on stale or wrong data, you’re making decisions about people based on a fiction, and they have a right to challenge it.
Storage Limitation
Keep personal data only as long as needed for the purpose. Define retention periods. Enforce them automatically. “We’ll deal with deletion when someone asks” is a process failure waiting to happen, particularly under the right to erasure.
Security Safeguards
Apply appropriate technical and organisational measures to protect data. This is where data protection sits as a discipline within the broader privacy framework. Encryption, access control, secure development practices, incident response: all of this is one principle among many. Security is necessary for privacy, but it is nowhere near sufficient.
Openness and Transparency
Distinct from the transparency in principle one (which is about how processing is communicated), this principle is about openness around your policies, practices, and developments. Where transparency in principle one is “tell people what you’re doing with their data”, openness is “be straightforward about how your organisation handles privacy as a whole.”
Individual Participation and Rights
Data subjects have rights: to know what data you hold about them, to access it, to correct it, to erase it, to restrict its processing, to receive it in portable form, and to object to it. We’ll go deeper on the technical implications of these rights in Part 2, because they have substantial engineering consequences that most teams underestimate.
Accountability
You must not only comply, you must be able to demonstrate compliance. Records of Processing Activities (ROPAs), Data Protection Impact Assessments (DPIAs), audit trails, documented policies, training records: the burden of proof sits with the controller, not the regulator. If you can’t show it, you haven’t done it.
Looking at this list, notice something important: Security Safeguards is one principle out of nine. Data protection, in its purest sense, is one ninth of privacy. That’s why I keep saying you can do data protection perfectly and still be deeply privacy-hostile.
Privacy by Design: The Bridge to Practice
Ann Cavoukian’s Privacy by Design framework was incorporated into Article 25 of the GDPR as “Data Protection by Design and by Default”. It captures something I’ve been banging on about across every series I’ve written: security and privacy properties must be established at design time, not bolted on at runtime.
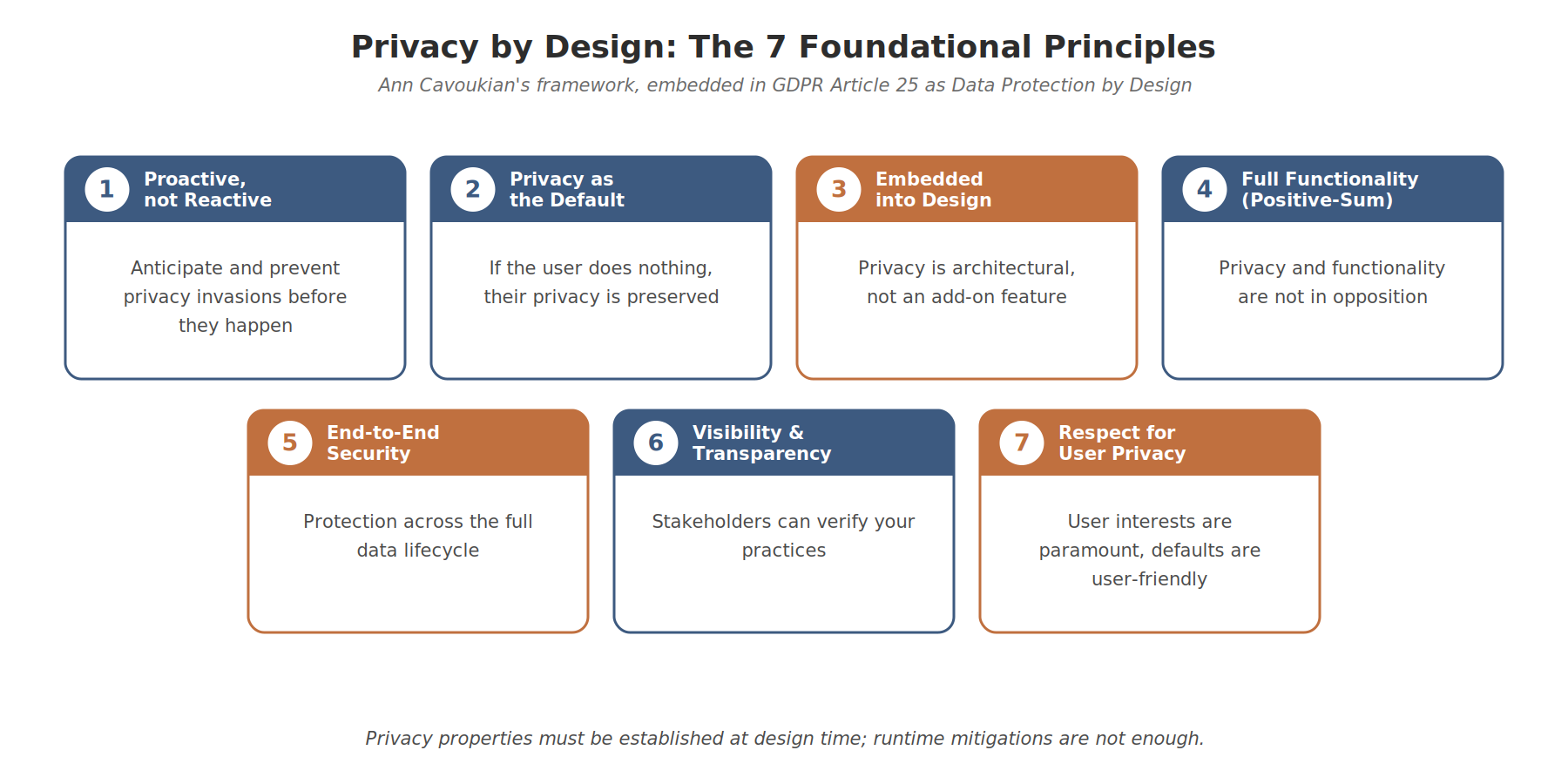
The 7 foundational principles are:
Proactive not Reactive; Preventative not Remedial. Anticipate and prevent privacy invasions before they happen, rather than offering remedies after the fact.
Privacy as the Default Setting. If the user does nothing, their privacy is preserved. No opting out required to achieve a reasonable baseline. The opposite of pre-ticked consent boxes and aggressive cookie banners.
Privacy Embedded into Design. Privacy is not an add-on. It’s part of the architecture, the data model, the API contracts, the access controls. If you can rip it out without the system falling over, it wasn’t embedded.
Full Functionality (Positive-Sum, not Zero-Sum). Privacy and functionality are not in opposition. You don’t have to trade one for the other. Most teams that claim “we’d love to be more private but the product wouldn’t work” haven’t actually tried.
End-to-End Security (Full Lifecycle Protection). Back to the data lifecycle. Privacy must be preserved from before collection through to secure destruction. Every phase.
Visibility and Transparency. Whatever you do with data, do it openly. Stakeholders should be able to verify your practices, not just take your word for them.
Respect for User Privacy (Keep it User-Centric). The user’s interests are paramount. Strong defaults, appropriate notices, user-friendly options. Not lawyer-friendly options dressed up to look user-friendly.
These principles are what should be sitting next to (or replacing) your existing design checklist. They’re what privacy looks like when it’s a structural property of your system rather than a compliance afterthought. And just like cryptographic agility or supply-chain trust scores, they’re worthless if they’re not actually implemented and measured.
What’s Coming in Part 2
In Part 2, we’ll move from principle to practice:
- Threat modelling for privacy. Lightly touching LINDDUN and T.R.I.M., and pointing to a deeper privacy threat modelling post.
- Dark patterns. Named (the patterns, anyway) and the principles they each violate.
- Data subject rights. What they are, why they matter, and the engineering implications most teams underestimate.
- Technical controls. Pseudonymisation versus anonymisation (and the gap most people miss), encryption in the post-quantum era, access control patterns, and a brief look at differential privacy.
- The data inventory. How to actually build one, what it needs to contain, and how it ties back to the supply chain trust scoring work from the previous series.
- AI, inference, and the privacy reckoning. Why everything above gets harder when statistical models start making decisions about humans, what the EU AI Act actually requires, and how this ties to the Elevation of Autonomy work.
- Ethics. What it means for an organisation to wear its values on its sleeve, not just print them on the about page.
Note to executives: if you’ve read this far, you should already be uncomfortable. Most organisations I see are confident in their data protection (encryption, firewalls, the box-ticking exercises) and ignorant of privacy. They mistake one ninth of the discipline for the whole thing. That’s not a technical gap, it’s a leadership gap. If the people setting your strategy can’t articulate the difference between protecting data and respecting privacy, your organisation will keep making decisions that are technically defensible and ethically indefensible. Part 2 will give you the practical tools. But the cultural change starts with naming the gap honestly.
Stay tuned!
You may also like:

Data Protection and Data Privacy - Part 2 of 2
From Principle to Practice: Privacy in the Real...

Get PQC Ready PDQ - Part 2
The Plan, the Order, and the Bill In...

Threat Modeling Your Dependencies - Part 2
Mitigating Third-Party Component Risk: Swapping the Cancer for...

Threat Modeling Your Dependencies - Part 1
How One Bad Library Can Poison Your Entire...