Ideas and Opinions from the Trenches


There are lots of ways we can optimise what we do, through a data driven approach, but we need to be careful and use critical and creative thinking.
Unrealistic beliefs
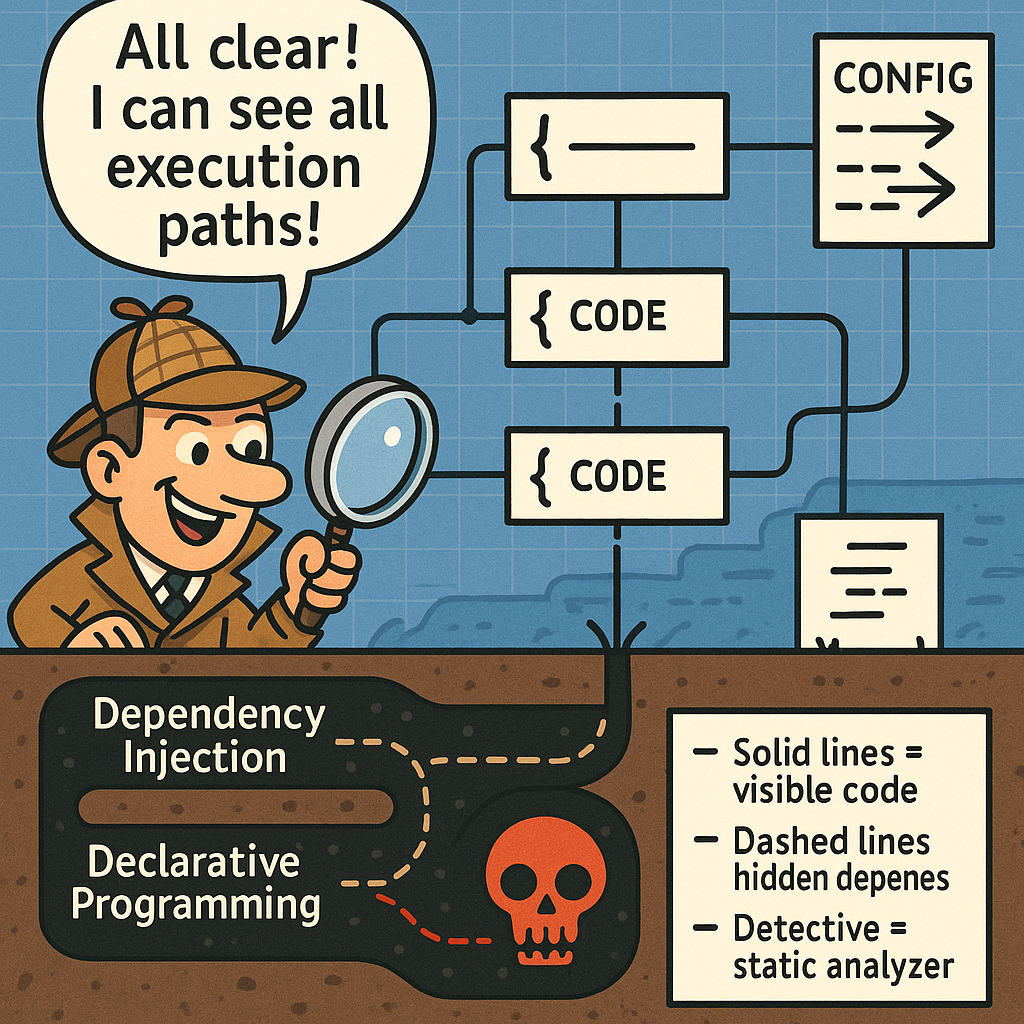
The Realities of Reachability: A Balanced Approach to Risk
Lately, there’s been a lot of buzz around reachability analysis. I’m absolutely in favor of reducing risk by confirming that certain vulnerable code paths aren’t actually accessible, but we need to be certain they truly aren’t.
I see two main camps emerging:
- Source Code Analysis Advocates: Some rely heavily on static analysis, but overlook the impact of declarative programming techniques or the complexities introduced by dependency injection. These approaches can easily create indirect paths that static tools will miss. Therefore you need to understand the strategy they use, if they come across an interface or abstract class the vulnerable code implements do they assume reachability or not?
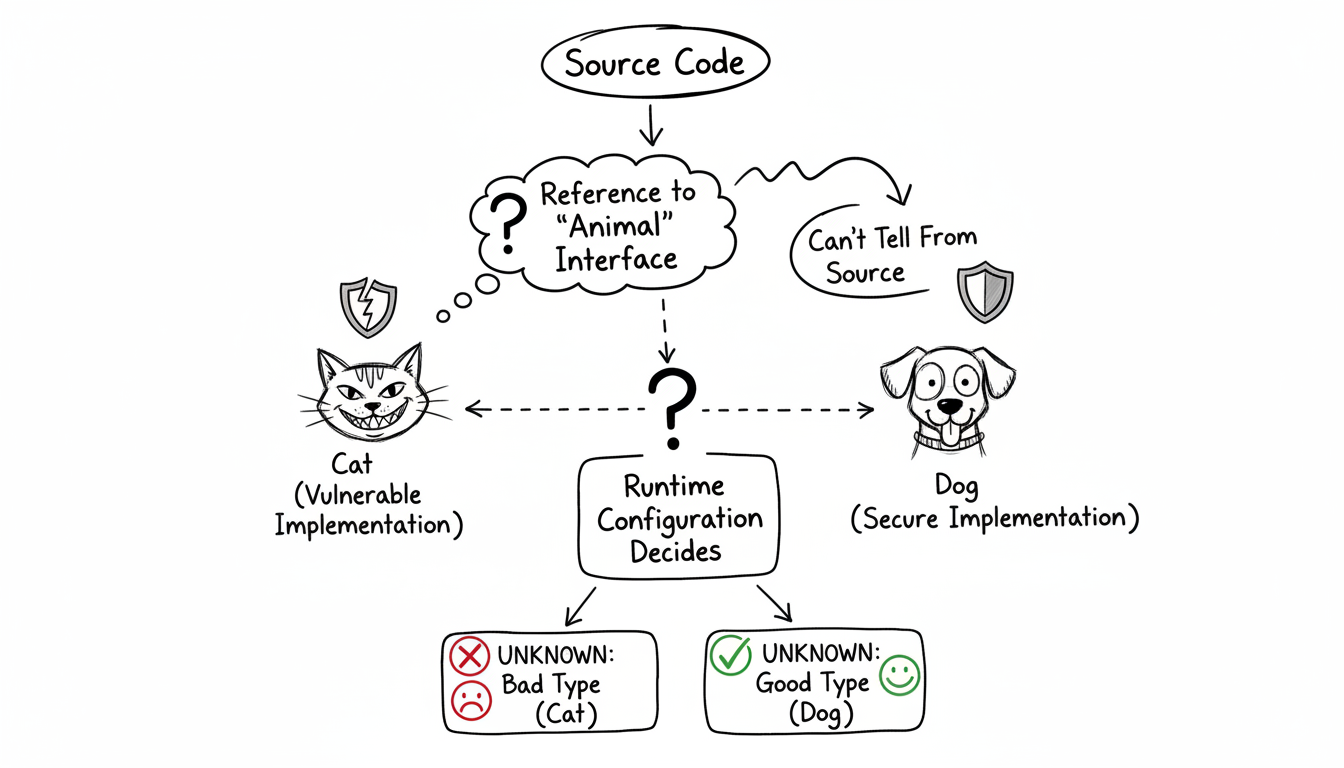
- Runtime Analysis Enthusiasts: Others prefer runtime analysis, often performed during testing. However, this can give a false sense of security if coverage isn’t comprehensive. Running in production is sometimes suggested, but even then, there’s no guarantee you’ll hit every obscure edge case in a reasonable timeframe.
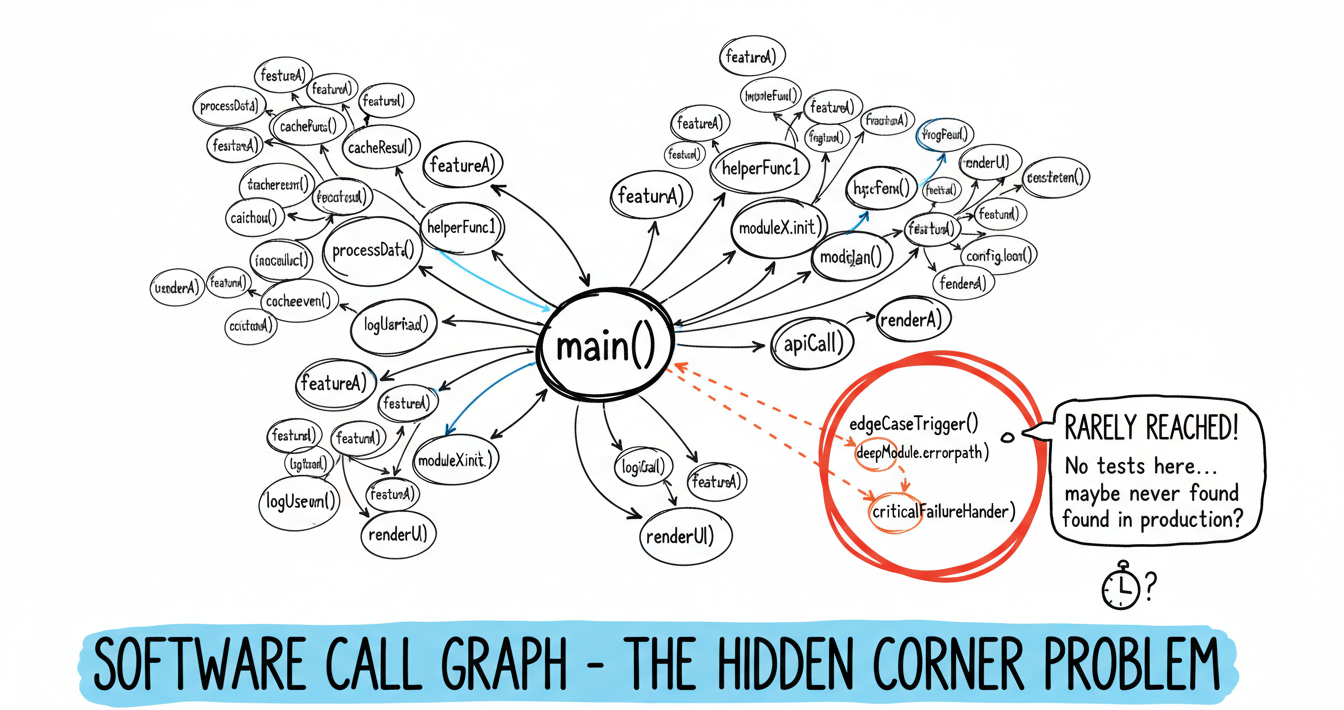
To really understand reachability, you need to combine both static and dynamic analysis, and even then, proceed with caution. Deciding not to patch a vulnerability simply because it appears “unreachable” is risky business, under the right (or wrong) conditions, that code path could become exploitable.
If your application has plugins that you can upload or you are on a servlet platform, servlets can also be added at runtime then your vulnerable library could be straight back in play. So ultimately reachability can confirm a vulnerability is exploitable and therefore must be prioritised but it cannot remove the need for remediation.
Some modern tools offer the ability to proactively block risky calls, using technologies like eBPF for example, which is a significant advantage. These solutions provide an additional safety net for anything you might have missed, but let’s be clear: this should always be the last line of defense, not the cornerstone of your security strategy.
Ultimately, a thoughtful, layered approach is the only way to ensure that “unreachable” truly means what it says.
Attack Surface and Prunning Weak Dependencies

Rethinking Dependency Bloat: Can We Be More Selective?
One pattern I see all too often is that the libraries we import are themselves pulling in a host of additional dependencies, many of which are only required for specific, sometimes rarely used, features. In many cases, these are technically “optional” dependencies, but they end up bundled in our applications regardless.
Wouldn’t it be better if we could eliminate these unnecessary components altogether?
Reachability analysis can certainly help here, highlighting which dependencies are actually in use. Still, it’s important to approach this carefully, removing dependencies without a full understanding of their impact can introduce its own risks. However, if you complement reachability analysis with extended runtime monitoring and gather enough evidence to confirm that certain libraries are truly unused, streamlining your dependency tree becomes a very realistic, and worthwhile, option.
It’s a practice that demands caution, but the payoff in reduced attack surface and improved maintainability is hard to ignore.
Which hurts most False Positives or False Negatives?

The Real Conversation We Need Around Application Security Tool Accuracy
Most application security vendors love to tout their low false positive rates. However, next time you’re talking to one, try asking about their false negative rate. The real goal should be achieving the right balance between precision and recall. To clarify: precision measures how many of the reported findings are actually relevant, while recall measures how many of the total actual issues the tool was able to detect.
A tool boasting zero false positives isn’t impressive if it only finds one vulnerability out of a hundred lurking in your codebase. On the other hand, if a tool flags everything as a vulnerability, you might as well be reviewing the code manuall, there’s no efficiency gained.
It’s time for marketers and sales teams to move away from selling false hope. In my experience, having put many of these tools through their paces, the results are often disappointing. We owe it to ourselves, and our users, to demand more than just polished stats and empty promises.
Graph analysis and Trustworthyness
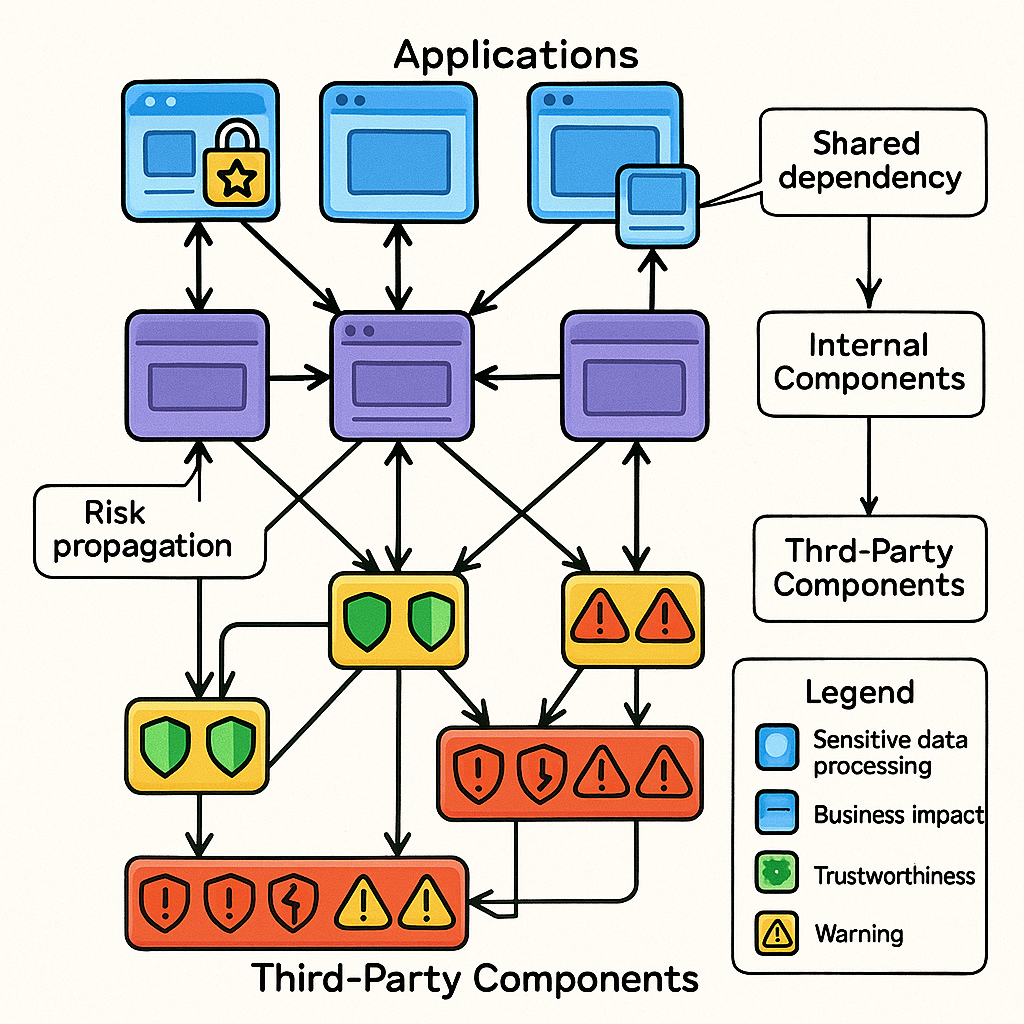
Using Graph Centrality to Drive Smarter Dependency Decisions
A while back, I wrote about graph centrality and how it can be leveraged to assess risk and prioritize remediation efforts in your codebase. If we take that concept a step further, graph centrality can also guide decisions about when and where to swap out libraries to reduce overall risk.
Let’s consider a practical example: imagine you have a core library that sits at the center of your application ecosystem. This library depends on four third-party libraries, each with a history of frequent critical vulnerabilities and a high mean time to remediate (MTTR), in other words, they’re slow to fix. Because of this, every application that relies on your central library is exposed to elevated risk.
Now, if you replace two or three of those risky dependencies with more trustworthy alternatives, ones with fewer critical vulnerabilities and a lower MTTR, you immediately lower your risk profile across all dependent applications. And if you can swap out all four for more reliable libraries, so much the better.
The key takeaway is that centrality isn’t just a theoretical metric; it’s a practical tool for making informed, risk-reducing decisions about your software supply chain. By focusing on the most central and most vulnerable nodes in your dependency graph, you can maximize the impact of your remediation efforts and build a more resilient foundation for your applications.